Custom Entity Recognition Model using Python spaCy
Train your Customized NER model using spaCy
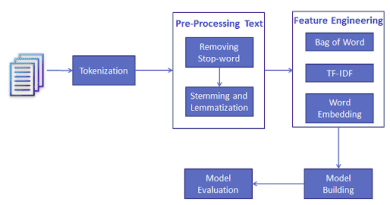
In the previous article, we have seen the spaCy pre-trained NER model for detecting entities in text. In this tutorial, our focus is on generating a custom model based on our new dataset.
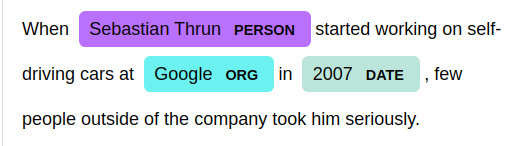
The entity is an object and a named entity is a “real-world object” that’s assigned a name such as a person, a country, a product, or a book title in the text that is used for advanced text processing. Entity recognition identifies some important elements such as places, people, organizations, dates, and money in the given text. Recognizing entities from text is helpful for analysts to extract useful information for decision-making. You can understand the entity recognition from the following example in the image:
Custom NER Model
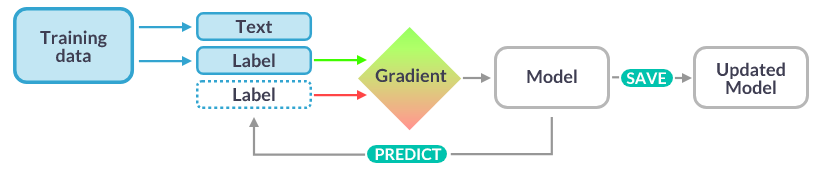
Let’s create the NER model in the following steps:
1. Load the dataset and Create an NLP Model
In this step, we will load the data, initialize the parameters, and create or load the NLP model. Let’s first import the required libraries and load the dataset.
# import the required libraries
import spacy
import randomNow, we will create a model if there is no existing model otherwise we will load the existing model. Let’s see the code below:
# Initial parameters
model_file = "ner_model" # set esisting model name other wise set it to None
iterations= 20
# Training data
TRAINING_DATA = [('what is the price of McVeggie?', {'entities': [(21, 29, 'FoodProduct')]}), ('what is the price of McEgg?', {'entities': [(21, 26, 'FoodProduct')]}), ('what is the price of McChicken?', {'entities': [(21, 30, 'FoodProduct')]}), ('what is the price of McSpicy Paneer?', {'entities': [(21, 35, 'FoodProduct')]}),
('what is the price of McSpicy Chicken?', {'entities': [(21, 36, 'FoodProduct')]}),]
# Testing sample data
test_sample='what is the price of McAloo?'
# Create NLP model
if model_file is not None:
" "
nlp = spacy.load(model_file)
print("Load Existing NER Model ", model_file)
else:
nlp = spacy.blank('en')
print("Created blank NLP model")2. Create an NLP Pipeline
In this step, we will create an NLP pipeline. First, we check if there is any pipeline existing then we use the existing pipeline otherwise we will create a new pipeline. Let’s see the code below:
# Create NLP Pipeline
if 'ner' not in nlp.pipe_names:
ner_pipe = nlp.add_pipe('ner')
else:
ner_pipe = nlp.get_pipe('ner')3. Add Entities Labels
In this step, we will add entities’ labels to the pipeline. First, we iterate the training dataset and then we add each entity to the model. Let’s see the code below:
# Add entities labels to the ner pipeline
for text, annotations in TRAINING_DATA:
for entity in annotations.get('entities'):
ner_pipe.add_label(entity[2])4. Train NER model
In this step, we will train the NER model. First, we disable all other pipelines and then we go only for NER training. In NER training, we will create an optimizer. after that, we will update nlp model based on text and annotations in the training dataset. This process continues to a defined number of iterations. Let’s see the code below:
from spacy.training.example import Example
# get names of other pipes to disable them during training
other_pipes = [pipe for pipe in nlp.pipe_names if pipe != 'ner']# train NER Model
with nlp.disable_pipes(*other_pipes): # only train NER
optimizer = nlp.begin_training()
for itn in range(iterations):
print("Iteration Number:" + str(itn))
random.shuffle(TRAINING_DATA)
losses = {}
for text, annotations in TRAINING_DATA:
# create example object
example = Example.from_dict(nlp.make_doc(text), annotations) # batch of texts and annotations
nlp.update([example],
drop=0.2,# dropout - make it harder to memorise data
sgd=optimizer, # callable to update weights
losses=losses)
print("Loss:",losses['ner'])5. Save and Test the model
In this step, we will save and test the NER custom model. to save the model we will use to_disk() method. For testing, first, we need to convert testing text into nlp object for linguistic annotations. Let’s see the code below for saving and testing the model:
# save model
model_file ="ner_model"
nlp.to_disk(model_file)# test model
test_document = nlp(test_sample)
for ent in test_document.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)Output: McAloo 21 27 FoodProduct
Summary
Congratulations, you have made it to the end of this tutorial!
In this tutorial, we have seen how to generate the NER model with custom data using spaCy. spaCy is built on the latest techniques and utilized in various day-to-day applications. It offers basic as well as NLP tasks such as tokenization, named entity recognition, PoS tagging, dependency parsing, and visualizations.
For more such tutorials, projects, and courses visit DataCamp
Reach out to me on Linkedin: https://www.linkedin.com/in/avinash-navlani/