
Big Data Interview Questions and Answers
Top 20 frequently asked Big Data interview questions and answers for freshers and experienced Data Engineers, ETL engineers, Data Scientists, and Machine learning engineers job roles.
Let’s see the interview questions and answers in detail.
1. What is Big Data?
Big data is a large amount of data that cannot be handled by traditional IT systems. It has the capability to generate value for business and growth.
Big data is high-volume, high-velocity, and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision-making, and process automation. — Gartner IT Glossary
2. What is Hadoop? Explain its features.
Hadoop is an open-source distributed computing framework for Big Data. Hadoop divides the big datasets into small chunks and executes them in a parallel fashion in a distributed environment. In this distributed system, data is processed across nodes or clusters of computers using parallel programming models. It scales processing from single servers to thousands of multiple machines. Hadoop has the capability of automatic failure detection and handling.
3. Explain Hadoop Architecture.
- A master node keeps all the information and metadata about Jobs and slaves. It coordinates all the execution of jobs. Slave nodes handle small blocks or chunks of data sent from the master node. They are kind of chunk servers.
- Job Distribution: Hadoop executes the MapReduce jobs and put the files into HDFS and keeps metadata in Task-Trackers.
- Data Distribution: Each node (mapper/reducer) maps whatever data is local to a particular node in HDFS. If the data size increases then HDFS automatically handles that and transfers data to other nodes.
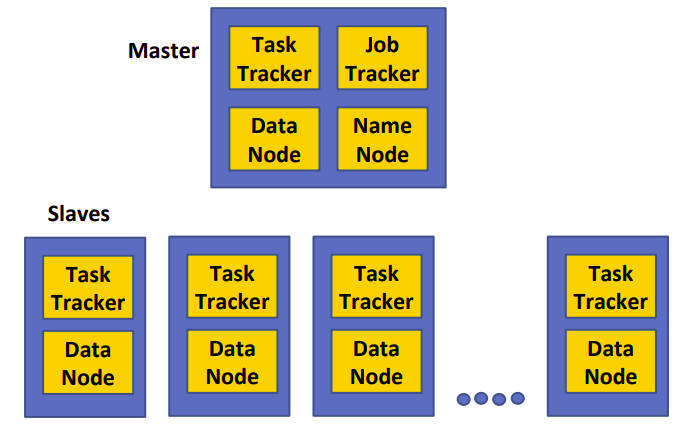
4. What is HDFS? Explain its components.
HDFS stands for Hadoop Distributed File System. HDFS is a file system inspired by Google File Systems and designed for executing MapReduce jobs. HDFS reads input data in large chunks of input, processes it, and writes large chunks of output. HDFS is written in Java. It is scalable and reliable data storage, and it is designed to handle large clusters of commodity servers.
There are two components of HDFS — name node and data node. HDFS cluster has a single NameNode that acts as the master node and Multiple DataNodes. NameNode manages the file system and regulates access to files. It controls and manages the services. DataNode provides block storage and retrieval services. Namenode maintains the file system and file Blockmap in memory. It keeps the metadata of any change in the block of data so that failure and system crash situations can be easily handled.
5. Explain the role of JobTracker and Task Tracker in Hadoop.
Job Tracker executes on a master node and Task Tracker executes on every slave node(the master node also have a Task Tracker). Each slave ties with processing (TaskTracker) and storage (DataNode).
The Job Tracker maintains records of each resource in the Hadoop cluster. it schedules and assigns resources to the Task Tracker nodes. It regularly receives the progress status from Task Tracker. The task tracker regularly receives execution requests from Job Tracker. The task tracker tracks each task(mapper or reducer) and updates the Job tracker about the workload. Task-Trackers’ main responsibility is to manage the processing resources on each slave node.
6. Explain the problem of a single point of failure(SPOF) in Hadoop?
NameNode holds the metadata for the whole Hadoop cluster environment. It means it keeps track of each DataNode and maintains its record. NameNode failure is considered a single point of failure(SPOF). If NameNode crashes due to the system, or hard drive failure complete cluster information will be lost.
7. Explain the role of Secondary NameNode?
We can recover from the situation of NameNode or SPOF by maintaining two NameNodes where one acts as a primary and the other NameNode acts as a secondary NameNode. It recovers by maintaining regular checkpoints on the Secondary NameNode. Here, Secondary NameNode is not a complete backup for the NameNode but it keeps the data of the primary NameNode. It performs a checkpoint process periodically.
8. What are active and standby or passive NameNodes?
Hadoop 2.0 offers high availability compared to Hadddop 1.X. It uses the concept of Standby Namenode. The standby NameNode is used to handle the problem of a Single Point of Failure(SPOF). The standby NameNode provides automatic failover of NameNode failure.
Here, Hadoop uses 2 NameNodes alongside one another so that if one of the Namenodes fails then the cluster will quickly use the other NameNode. In this standby NameNOde concept, DataNode sends all the signals to both the NameNodes and keeps a shared directory in Network File System.
9. Explain different types of modes in Hadoop.
Hadoop can run in 3 different modes.
1. Standalone(Local) Mode: By default, Hadoop is configured to run in a no distributed mode. It runs as a single Java process. Instead of HDFS, this mode utilizes the local file system. This mode is useful for debugging and there isn’t any need to configure core-site.xml, hdfs-site.xml, mapred-site.xml, masters & slaves. Stand-alone mode is usually the fastest mode in Hadoop.
2. Pseudo Distributed Mode(Single node): Hadoop can also run on a single node in a Pseudo Distributed mode. In this mode, each daemon runs on a separate java process. In this mode, a custom configuration is required( core-site.xml, hdfs-site.xml, mapred-site.xml ). Here HDFS is utilized for input and output. This mode of deployment is useful for testing and debugging purposes.
3. Fully Distributed Mode: This is the production mode of Hadoop. In this mode typically one machine in the cluster is designated as NameNode and another as Resource Manager exclusively. These are masters. All other nodes act as Data Nodes. These are the slaves. Configuration parameters and environment need to be specified for Hadoop Daemons. This mode offers fully distributed computing capability, reliability, fault tolerance, and scalability.
10. What is rack awareness in Hadoop?
A rack is a type of storage area that hosts the entire physical collection of DataNodes in a single location. The file blocks and their replicas are stored on DataNodes. In a large Hadoop cluster, we can have multiple racks.
NameNode maintains the details of DataNodes and rack ids in their dataset. Rack awareness is the concept of keeping track of DataNode details in an information base at NameNode. Rack awareness helps in reducing traffic and latency, improving fault tolerance, and achieving high availability of data.
11. What is MapReduce? Explain it’s working.
MapReduce has two basic operations: The first operation is applied to each of the input records, and the second operation aggregates the output results. Map-Reduce must define two functions:
- Map function: It reads, splits, transforms, and filters input data.
- Reduce function: It shuffles, sorts, aggregates, and reduces results.
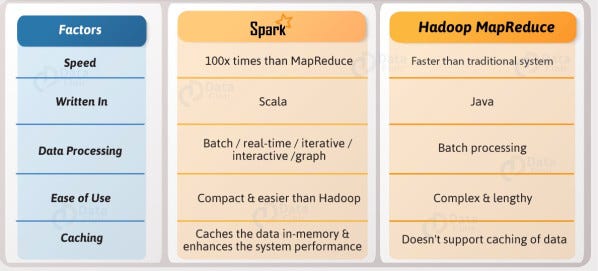
12. Explain the differences between MapReduce Vs Spark.
One of the major drawbacks of MapReduce is that it permanently stores the whole dataset on HDFS after executing each task. This operation is very expensive due to data replication. Spark doesn’t write data permanently on a disk after each operation. It is an improvement over Mapreduce. Spark uses the in-memory concept for faster operations. This idea is given by Microsoft’s Dryad paper.
The main advantage of spark is that it launches any task faster compared to MapReduce. MapReduce launches JVM for each task while Spark keeps JVM running on each executor so that launching any task will not take much time.
13. What are the differences between NTFS and HDFS?
- NTFS stores files in a local file system, while HDFS stores files in a distributed environment across the cluster machines.
- In NTFS, data is not replicated, while in HDFS, data is replicated.
- Scaling up is not possible in NTFS, but horizontal and vertical scaling are possible in HDFS.
- In NTFS, the block size lies between 512 bytes and 64 KB, while in HDFS, the block size is fixed at 64 MB.
14. What are the differences between RDMBS and HDFS?
- RDBMS is used for structured data, while HDFS can store both structured and unstructured data.
- RDBMS can handle a few thousand records, while HDFS can handle millions or billions of records.
- RDBMS is best suited for transaction management, while HDFS is best suited for analytics purposes.
- RDBMS data must be normalized, while HDFS has no normalization concept.
- In RDBMS, consistency is preferred over availability, while in HDFS, availability is preferred over consistency.
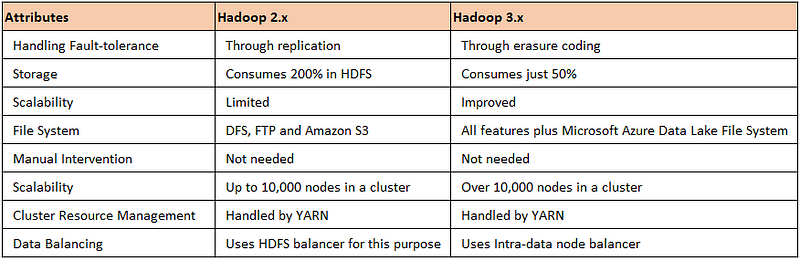
15. Compare the differences between Hadoop 2. x, and Hadoop 3.x?
Hadoop 2.x keeps 3 replicas by default for handling any kind of failure. This is a good strategy for data locality but keeping multiple copies extra overhead and slow down the overall throughput. Hadoop 3.x storage solved this 200% overhead by using erasure coding storage. It is cost-effective and saves IO operation time.
First, we split the data into several blocks in HDFS, and then we pass it to the Erasure encoding. Erasure Encoding output several parity blocks. A combination of data and parity bock is known as an encoding group and in case of a failure, the erasure decoding group reconstructs the original data.
16. What is Apache Pig and Why do we need it?
Hadoop is written in Java and initially, most of the developers write map-reduce jobs in Java. It means till then Java is the only language to interact with the Hadoop system. Yahoo came with one scripting language known as Pig in 2009. Here are a few other reasons why Yahoo developed the Pig.
- Lots of on-Programmers were unable to utilize MapReduce because they didn’t know the Java programming language.
- It is difficult to maintain, optimize and write productive code.
- It is also difficult to consider all the MapReduce phases such as map, sort, and reduce during programming.
Yahoo’s managers have faced problems in performing small tasks. For each small and big change, they need to call the programming team. Also, programmers need to write lengthy codes for small tasks. To overcome these problems, yahoo developed a scripting platform Pig. Pig help researchers analyze data with simple and few lines of declarative syntax.
17. What is Apache HBase? Compare relational database and HBase.
HBase is a column-oriented, open-source, NoSQL, and distributed database management system modeled after Google’s Bigtable that executes on top of the HDFS. HBase stores sparse data sets in a fault-tolerant way. HBase is suitable for real-time data processing on large volumes of datasets.
HBase is not like an RDBMS because it does not support structured data storage like SQL. HBase is written in Java, just like Hadoop.
18. What is Hive in Hadoop?
Hive is a component in Hadoop Stack. It is an open-source data warehouse tool that runs on top of Hadoop. It was developed by Facebook and later it is donated to the Apache foundation. It reads, writes, and manages big data tables stored in HDFS or other data sources.
Hive doesn’t offer insert, delete and update operations but it is used to perform analytics, mining, and report generation on the large data warehouse. Hive uses Hive query language similar to SQL. Most of the syntax is similar to the MySQL database. It is used for OLAP(Online Analytical Processing) purposes.
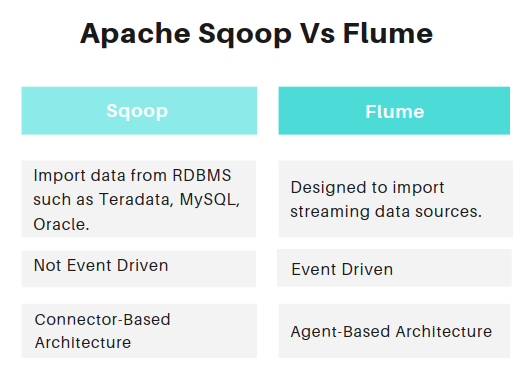
19. Explain Apache Flume and Sqoop.
Flume is a data ingestion tool that plays a critical role in importing data for processing & analysis. There can be multiple streaming and other sources from which data can be collected.
Before Sqoop, the developer needs to write the MapReduce program to extract and load the data between RDBMS and Hadoop HDFS.
20. What is Apache ZooKeeper?
ZooKeeper is an open-source, centralized service configuration service, and naming registry for distributed systems. It provides configuration details, a naming registry, cross-node synchronization, and group-related services in a large, distributed cluster environment.
The main objective of ZooKeeper is to share reliable information across the large cluster. It helps applications synchronize their tasks across large, distributed clusters.
Summary
In this article, we have focused on Big Data interview questions and answers. In the following article, we will focus on the interview questions related to Apache Spark and PySpark.


