
Data Science Interview Questions Part-8(Deep Learning)
Top-25 frequently asked data science interview questions and answers on Deep Learning for fresher and experienced Data Scientist, Data analyst, statistician, and machine learning engineer job role.
Data Science is an interdisciplinary field. It uses statistics, machine learning, databases, visualization, and programming. So in this 8th article, we are focusing on Deep Learning interview questions. Let’s see the interview questions and answers in detail.
1. What is Deep Learning?
Deep Learning is a subdomain of Machine Learning. In deep learning, a large number of layers in the architecture. These successive layers learn more complex patterns in the data. Deep Learning offers various applications in text, voice, image, and video data.
2. What is Gradient Descent? How does it work?
It is a first-order iterative optimization technique for finding the minimum of a function. It is an efficient optimization technique to find a local or global minimum.
In gradient descent, gradient and step are taken at each point. It takes the current value of parameters and updates it with the help of gradient and step width. the gradient is recomputed again and steps decremented in each iteration. This process continues until the convergence achieved.
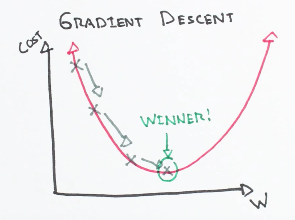
Types of Gradient Descent
- Full batch gradient descent uses a full dataset.
- Stochastic gradient descent uses a sample of the dataset.
3. What is the Cost Function?
The main objective of the neural network is to find the optimal set of weights and biases by minimizing the cost function. Cost function or loss function is a measure used to measure the performance of the neural network on test data set. It measures the ability to estimate the relationship between X and y. An example of cost functions is the mean square error.
4. What is the activation function? Why do we need them?
Activation functions are mathematical functions that transform the output of a neural network on a certain scale. It means it normalizes the output between range 0 and 1 or -1 and 1. Activation functions in neural networks introduce non-linearity. It helps neural networks to handle non-linear relationships.
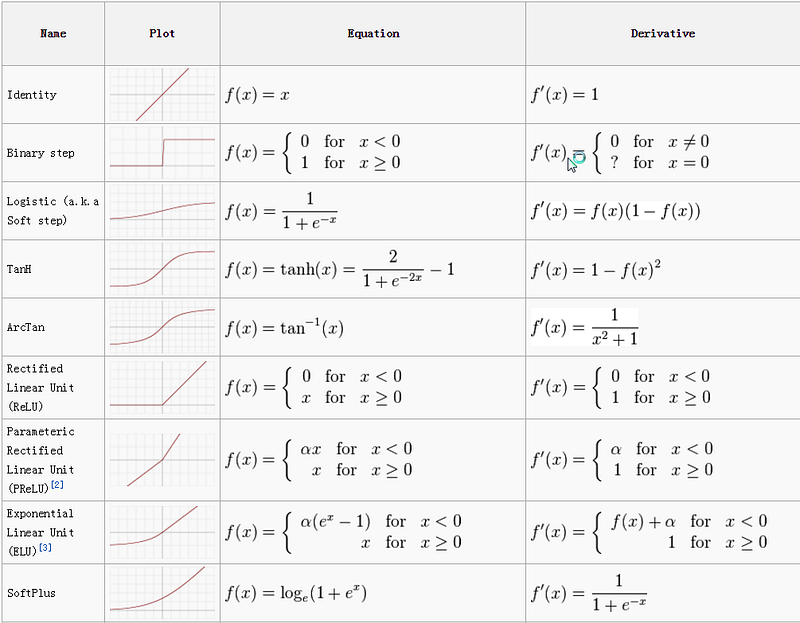
5. Why is the ReLU activation function is better than the sigmoid activation function?
Sigmoid function bounded between 0 and 1. It is differentiable, non-linear, and produces non-binary activations. But the problem with Sigmoid is the vanishing gradients.
ReLu(Rectified Linear Unit) is like a linearity switch. If you don’t need it, you “switch” it off. If you need it, you “switch” it on. ReLu avoids the problem of vanishing gradient.
ReLu also provides the benefit of sparsity and sigmoids result in dense representations. Sparse representations are more useful than dense representations.
6. What is the use of the leaky ReLU function?
The main problem with ReLU is, it is not differentiable at 0 and may result in exploding gradients. To resolve this problem Leaky ReLu was introduced that is differentiable at 0. It provides small negative values when input is less than 0.
7. What is the “dying ReLU” problem in neural networks?
When ReLu provides output zero for any input(large negative biases). This problem will occur due to a high learning rate and large negative bias. Leaky ReLU is a commonly used method to overcome a dying ReLU problem. It adds a small negative slope to prevent the dying ReLU problem.
8. Why Tanh activation function preferred over sigmoid?
Tanh function is called a shifted version of the sigmoid function. The output of Tanh centers around 0 and sigmoid’s around 0.5. Tanh Convergence is usually faster if the average of each input variable over the training set is close to zero.
When you struggle to quickly find the local or global minimum, in such case Tanh can be helpful in faster convergence. The derivatives of Tanh are larger than Sigmoid that causes faster optimization of the cost function. Tanh and Sigmoid both suffered from vanishing gradient problems.
9. What is the difference between model parameters and hyperparameters?
Model parameters are internal and can be estimated from data. Model hyperparameters are external to the model and can not be estimated from data.
10. What is backward and forward propagation?
Backpropagation or backward pass traverses in the reverse direction. It computes the gradient(or delta rule) of parameters(weights and biases) in order to map the output layer to the input layer. The main objective of backpropagation is to minimize the error. This process will repeat until the error is minimized and final parameters will be used for producing the output.
Forward propagation or forward pass computes the intermediate values in order to map the input and output layer.
11. What do you mean by Dropout and Batch Normalization?
Dropout is a technique for normalization. It drops out or deactivates some neurons from the neural network to remove the problem of overfitting. In other words, it introduces the noise in the neural network so that model is capable to generalize the model.
Normalization is used to reduce the algorithm time that spends on the oscillation on different values. It brings all the features on the same input scale.
Batch Normalization is also normalizing the values but at hidden states on small batches of data. The research has shown that removing Dropout with Batch Normalization improves the learning rate without loss in generalization.
12. What is RNN? and How does an RNN work?
Recurrent neural networks(RNN) work on sequential input data with a good amount of accuracy. It uses a backpropagation network for back-propagating the error and gradient. In RNN, backpropagation is known as backpropagation through time(BPTT).
13. What is vanishing gradient descent?
RNN follows the chain rule in its backpropagation. When one of the gradients approaches zero then all the gradient will move towards zero. This small value is not sufficient for training the model. Here, a small gradient means that weights and biases of the neural network will not be updated effectively.
Also, at hidden layers activation functions such as sigmoid function and Tanh causes small derivatives that decrease the gradient.
The solution to Vanishing Gradient Descent
- Use a different activation function such as ReLu(Rectified Linear Unit).
- Batch normalization can also solve this problem by simply normalizing the input space.
- Weight initialization
- LSTM
14. What is exploding gradient descent?
Exploding gradient is just an opposite situation of vanishing gradient. A too-large value of RNN causes powerful training. We can overcome this problem by using Truncated Backpropagation, penalties, Gradient Clipping.
15. What is LSTM and BiLSTM?
LSTM is a special type of RNN. It also uses a chain-like structure but it has the capability to learn and remember long-term sequences. LSTM handles the issue of vanishing gradient. It keeps gradient step enough and therefore the short training and the high accuracy. It uses gated cells to write, read, erase the value. It has three gates: input, forget, and output gate.
BiLSTM learns sequential long terms in both directions. It captures the information from both the previous and next states. Finally, it merges the results of two states and produces output. It memorizes information about a sentence from both directions.
16. Explain gates used in LSTM with their functions.
LSTM has three gates: input, forget, and output gate. The input gate is used to add the information to the network, forget used to discard the information, and the output gate decides which information pass to the hidden and output layer.
17. What is the difference between LSTM and GRU?
GRU is also a type of RNN. It is slightly different from LSTM. The main difference between LSTM and GRU Gates is the number of gates.
- LSTM uses three gates(input, forget, and output gate) while GRU uses two gates(reset and update).
- In GRU, the update gate is similar to the input and forget gate of LSTM and the reset gate is another gate used to decide how much past information to forget.
- GRU is faster compared to LSTM.
- GRU needs fewer data to generalize.
18. What is CNN? How does CNN work?
CNN is Feedforward neural network. CNN filters the raw image detail patterns and classifies them using a traditional neural network. Convolution focuses on small patches in the image and represents a weighted sum of image pixel values. It offers applications in Image recognition and object detection. It works in the following steps:
- Convolution Operation
- ReLu layer
- Pooling- Max and Min Pool
- Flattening
- Full connection
19. What are Convolution layers?
The convolution layer is inspired by the visual cortex. It converts the image into layers, transforms into small images, and extracts features from images. It will sum up the results into a single output pixel. It captures the relationship between pixels and detects edge, blur, and sharpen features.
20. What is padding?
Sometimes filter unable to fit the input image perfectly. We have two strategies for padding: Zero padding and valid padding. Zero paddings add zero so that the image filter fits the image. Valid padding drops the part of the image. (Drop the part of the image)
21. What are pooling and Flattening?
Pooling is used to reduce the spatial size and selects the important pixel values as features. It is also known as Downsampling. It also makes faster computation by reducing its dimension. Pooling summarizes the sub-region and captures rotational and positional invariant features.
22. What is Epoch, Batch, and Iteration in Deep Learning?
- Epoch is a one-pass to the entire dataset. Here, one pass = one forward pass + one backward pass
- Batch size is the number of training examples in one forward/backward pass. The larger batch size requires more memory space.
- Iteration is the number of passes. If each pass using batch size then the number of times a batch of data passed through the algorithm.
- For example, if you have 1000 training examples, and your batch size is 200, then it will take 5 iterations to complete 1 epoch.
23. What is an Auto-encoder?
Autoencoders are unsupervised deep learning techniques that reduce the dimension of data to encode. Autoencoders encoded the data on one side and decoded it on another side. After encoding, it transforms data into a reduced representation called code or embedding(also known as latent-space representation). This embedding then transformed into the output. Autoencoders can do dimensionality reduction and improve the performance of the algorithm.
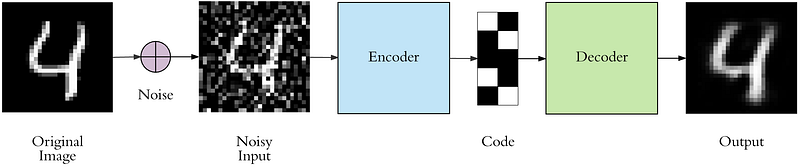
24. What do you understand by Boltzmann Machine and Restricted Boltzmann Machines?
Boltzmann machines are stochastic(non-deterministic models) and generative neural networks. It has the capability to discover the interesting features that represent complex patterns in the data. Boltzmann Machine uses many layers for feature detectors that makes it slower network. Restricted Boltzmann Machines (RBMs) have a single layer of feature detectors that makes it faster compared to Boltzmann Machine.
RBM is a neural network model are also known as Energy Based Models. RBM offers various applications in recomender system, classification, regression, topic modeling and dimensionality reduction.
25. Explain Generative Adversarial Network.
GAN (Generative Adversarial Network) is unsupervised deep learning that trains two networks at the same time. It has two components: Generator and Discriminator. The generator generates the images close to the real image and the discriminator determines the difference between fake and real images. GAN is able to produce new content.
Summary
In this article, we have focused on Deep Learning interview questions and answers. In the next article, we will focus on the interview questions related to Big Data.
Data Science Interview Questions Part-9(BigData)


