MapReduce Algorithm
In this tutorial, we will focus on MapReduce Algorithm, its working, example, Word Count Problem, Implementation of wordcount problem in PySpark, MapReduce components, applications, and limitations.
Map-Reduce is a programming model or framework for processing large distributed data. It processes data that resides on hundreds of machines.
It is a simple, elegant, and easy-to-understand programming model. It is based on the parallel computation of the job in a distributed environment. It processes a large amount of data in a reasonable time. Here, distribution means parallel computing of the same task on each CPU with a different dataset. MapReduce program can be written in JAVA, Python, and C++.
MapReduce Algorithm
MapReduce has two basic operations: The first operation is applied to each of the input records, and the second operation aggregates the output results. Map-Reduce must define two functions:
- Map function: It reads, splits, transforms, and filters input data.
- Reduce function: It shuffles, sorts, aggregates, and reduces the results.
How Does MapReduce Algorithm Work?
MapReduce has two steps: map and reduce. map phase load, parse, transform, and filter the data. The map tasks generally load, parse, transform, and filter data. Each reduced task handles the results of the map task output.
Map task takes a set of input files that are distributed over HDFS. These files were divided into byte-oriented chunks. Finally, these chunks were consumed by the map task. The map task performs the following sub-operations: read, map, combine, and partition. The output of map tasks is a combination of a key-value pair that is also intermediate key-values.
The reduce phase takes the output of the map phase as input and converts it into final key-value pairs. The reduce task performs the following sub-operations: shuffle, sort, and reduce.
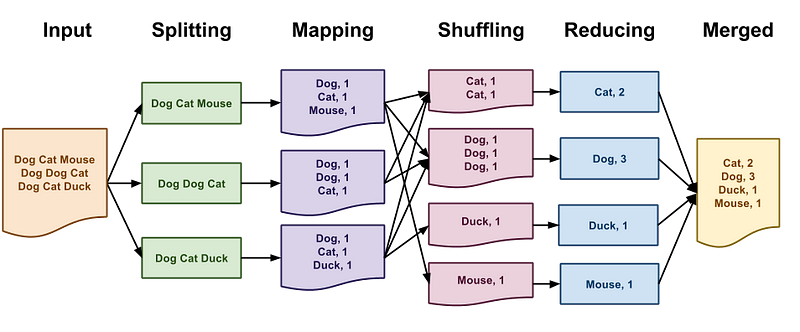
Word Count Problem
In this problem, we have to count the frequency of each word in the given large text files. In the map phase, the file is broken into sentences, and each sentence will split into tokens or words. after tokenization, the map converts it into a key values pair. and each key-value pair is known as an intermediate key-value pair.
In the reduce phase, the intermediate key-value pair is shuffled and grouped based on the key in the key-value pair. After shuffle and group, pairs were aggregated and merged based on similar keys.
PySpark Implementation of Word Count problem
In this step, we have solved the word count problem using the MapReduce algorithm. We have executed this code in the Databricks community edition.
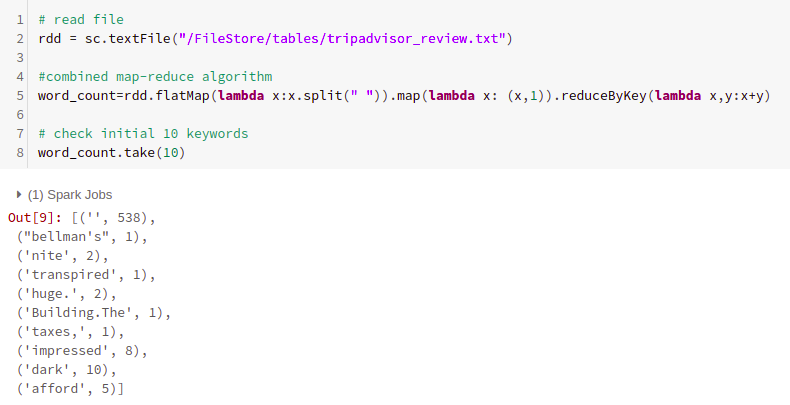
# read file
rdd = sc.textFile(“/FileStore/tables/tripadvisor_review.txt”)
#combined map-reduce algorithm
word_count=rdd.flatMap(lambda x:x.split(“ “)).map(lambda x: (x,1)).reduceByKey(lambda x,y:x+y)
# check initial 10 keywords
word_count.take(10)
MapReduce Components
Reader
The reader reads the input records and parses it into the key-value pairs. These pairs pass to the mapper.
Mapper
The mapper function takes the key-value pairs as input, processes each pair, and generates the output intermediate key-value pairs. Both the input and output of the mapper are different from each other.
Partition
Partition takes intermediate key/value pairs as input and splits them into shards. It distributes the keys evenly in a way that similar keys are grouped onto the same reducer.
Shuffle & sort
The main objective of this step is to group similar key items so that the reducer can easily aggregate them. This step is performed on the reducer. It takes input files written by partitioners and arranges them in a group for aggregation purposes at the reducer.
Reducer
The reducer takes the shuffled and sorted data for aggregation purposes. It performs an aggregate operation on grouped data.
Applications
We can use MapReduce to solve problems that are “huge but not hard”. It means your dataset can be large enough but your problem should be simple. If your problem can be converted into the key-value pairs, it needs only aggregate and filter operations, and operations can be executed in isolation.
MapReduce has the following applications:
- Web Crawling and Search Engines
- Advertisements Targeting Platforms
- Financial firms use MapReduce to identify risk, analyze fraudulent activities, and target marketing campaigns.
- Preventive Maintenance
- Supply Chain Monitoring
- Public Health Monitoring
- Recommendation Engine
Limitations
- the type of problem where the computation of a value depends on previously computed values, then MapReduce can not be used. For example, the Fibonacci series where each value is a summation of the previous two values. i.e., f(k+2) = f(k+1) + f(k).
- It does not work with real-time systems.
- It will also not be good for graphs, iterative, and incremental types of problems.
- For tasks that are sequential and cannot be parallelized, such problems are not possible through MapReduce.
Conclusion
Congratulations, you have made it to the end of this tutorial!
In this tutorial, we will focus on the MapReduce Algorithm, its working, example, Word Count Problem, Implementation of wordcount problem in PySpark, MapReduce components, applications, and limitations.
I look forward to hearing any feedback or questions. You can ask a question by leaving a comment, and I will try my best to answer it.