
Hadoop Distributed File System
Hadoop is a Big Data computing platform for handling large datasets. Hadoop has a core two components: HDFS and MapReduce. In this tutorial, we will focus on the HDFS (Hadoop Distributed File System). HDFS is a storage component of Hadoop, It is a Distributed File System. It is optimized for high throughput and replicates blocks for failure handling.
HDFS
HDFS stands for Hadoop Distributed File System. HDFS is a file system that is inspired by Google File Systems and designed for executing MapReduce jobs. HDFS reads input data in large chunks of input, processes it, and writes large chunks of output. HDFS is written in Java. It is scalable and reliable data storage, and it is designed to handle large clusters of commodity servers.
HDFS Features
- HDFS is suitable for distributed storage and processing.
- Hadoop provides a CLI to interact with HDFS.
- HDFS provides file permissions and authentication services.
- Scaling wide and scaling deep
- Automatic fault tolerance
HDFS Terminology
- Job is a “full program” that executes a Mapper and Reducer across a data set.
- The task is an executed form of a Mapper or a Reducer on a slice of data.
- Job-Tracker instance runs on the master node that accepts job requests from clients.
- Task-Tracker instances run on slave nodes. It instantiates the separate process for each task.
How Hadoop Works?
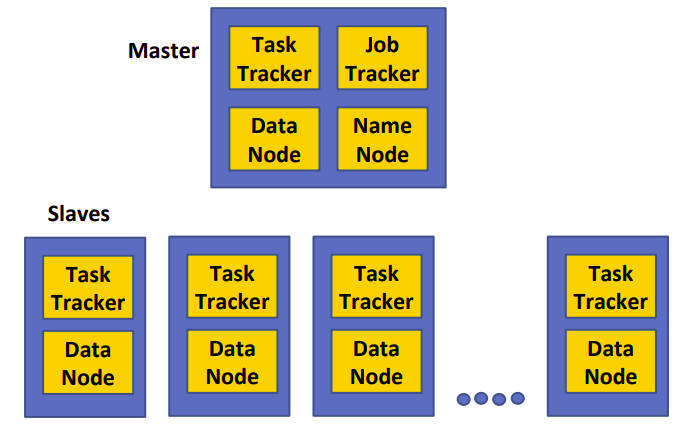
- A master node keeps all the information and metadata about Jobs and slaves. It coordinates all the execution of jobs. Slave nodes handle small blocks or chunks of data sent from the master node. They are kind of chunk servers.
- Job Distribution: Hadoop executes the MapReduce jobs and put the files into HDFS and keep metadata into Task-Trackers.
- Data Distribution: Each node (mapper/reducer) maps whatever data is local to a particular node in HDFS. If the data size is increase then HDFS automatically handles that and transfers data to other nodes.
NameNode and DataNode
HDFS cluster has a single NameNode that acts as the master node and Multiple DataNodes. NameNode manages the file system and regulates access to files. It controls and manages the services. DataNode provides block storage and retrieval services. Namenode maintains the file system and file Blockmap in memory. It keeps the metadata of any change in the block of data so that failure and system crash situations can be easily handled.
Job Tracker and Task Tracker
Job Tracker executes on a master node and Task Tracker executes on every slave node(master node also have a Task Tracker). Each slave ties with processing (TaskTracker) and the storage (DataNode).
The Job Tracker maintains records of each resource in the Hadoop cluster. it schedules and assigns resources to the Task Tracker nodes. It regularly receives the progress status from Task Tracker. The task tracker regularly receives execution requests from Job Tracker. Task tracker tracks each task(mapper or reducer) and updates Job tracker about the workload. Task-Trackers’ main responsibility is to manage the processing resources on each slave node.
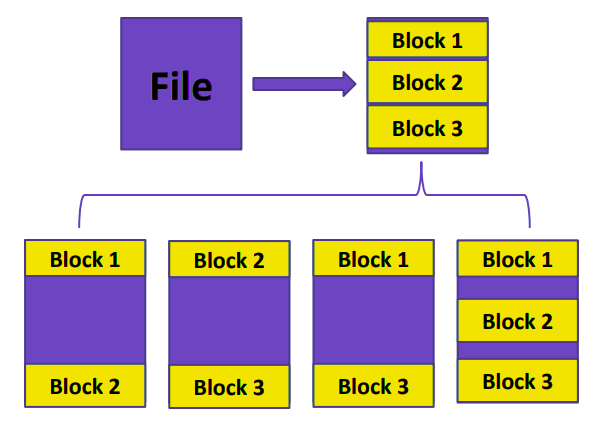
Data Replication
In HDFS, each file is broken into equal size of blocks. Blocks are replicated to handle fault tolerance. NameNode continuously receives a Heartbeat or status update and a data block report from each DataNode in the cluster.
Handling DataNode Failure
DataNode failure means the failure of the slave node. DataNode periodically passes a signal or heartbeat to NameNode. It is helpful to tress the DataNode working status. When NameNode does not receive any heartbeat signals from DataNode then it assumes that DataNode is dead. After that, NameNode transfers the load of the current dead DataNode to other DataNode.
Handling NameNode Failure or Single Point of Failure (SPOF)
NameNode holds the metadata for the whole Hadoop cluster environment. It means it keeps track of each DataNode and maintains its record. NameNode failure is considered as a single point of failure(SPOF). If NameNode crashes due to system, hard drive failure whole cluster information will be lost.
Why is the NameNode a single point of failure? What is bad or difficult about having a complete duplicate of the NameNode running as well?
Handling NameNode Failure using Secondary NameNode
We can recover from the situation of NameNode or SPOF by maintaining two NameNodes where one acts as a primary and the other NameNode acts as a secondary NameNode. It recovers by maintaining regular checkpoints on the Secondary NameNode. Here, Secondary NameNode is not a complete backup for the NameNode but it keeps the data of primary NameNode. It performs a checkpoint process periodically.
The main problem with the secondary NameNode is that it does not provide automatic failure recovery. It means in case of Namenode failure, the Hadoop administrator needs to take manually recover the data from Secondary Namenode.
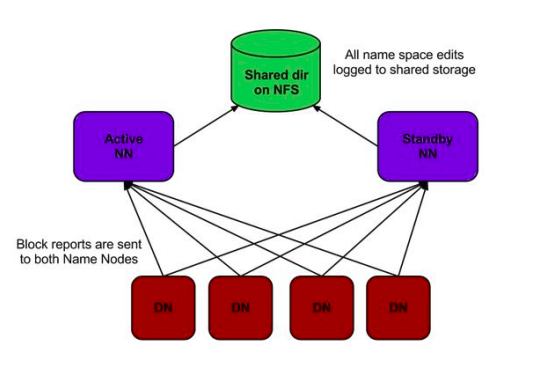
Handling NameNode Failure using Standby Namenode (Hadoop 2.0)
Hadoop 2.0 offers high availability compare to Hadddop 1.X. It uses the concept of Standby Namenode. The standby NameNode is used to handle the problem of a Single Point of Failure(SPOF). The standby NameNode provides automatic failover of NameNode failure.
Here, Hadoop uses 2 NameNodes alongside one another so that if one of the Namenodes fails then the cluster will quickly use the other NameNode. In this standby NameNOde concept, DataNode sends all the signals to both the NameNodes and keeps a shared directory in Network File System.
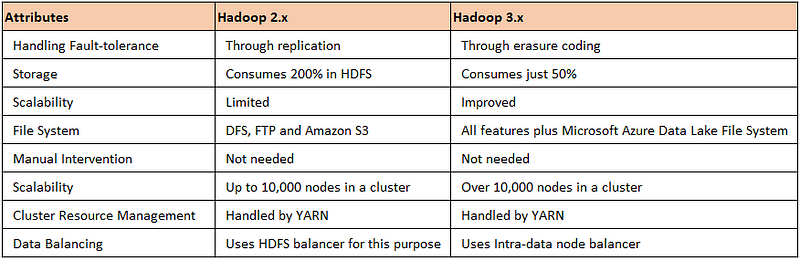
Hadoop 2.X vs Hadoop 3.X
Hadoop 2.x keeps 3 replicas by default for handling any kind of failure. This is a good strategy for data locality but keeping multiple copies extra overhead and slow down the overall throughput. Hadoop 3.x storage solved this 200% overhead by using erasure coding storage. It is cost-effective and saves IO operation time.
First, we split the data into several blocks in HDFS, and then we pass to the Erasure encoding. Erasure Encoding output several parity blocks. A combination of data and parity bock is known as an encoding group and in case of a failure, the erasure decoding group reconstructs the original data.
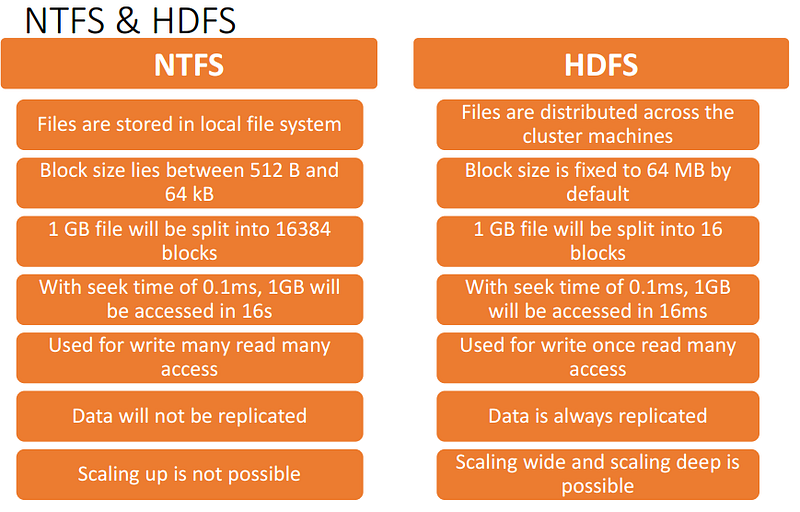
NTFS vs HDFS
RDBMS vs HDFS

Conclusion
Congratulations, you have made it to the end of this tutorial!
In this tutorial, you have covered a lot of details about HDFS. What is HDFS?, its features, how Hadoop works?, NameNode, DataNode, Job-Tracker, Task-Tracker, Data Replication, Handling DataNode, and NameNode Failure, Hadoop, 2.X, and Hadoop 3.X. Also, discussed the comparison of HDFS with NTFS and RDBMS.
Hopefully, you can now utilize the HDFS knowledge in your big data and data science career. Thanks for reading this tutorial!


