
Introduction to Apache Spark
In this tutorial, we will focus on Spark, Spark Framework, its Architecture, working, Resilient Distributed Datasets, RDD operations, Spark programming language, sand comparison of Spark with MapReduce.
Spark is a fast cluster computing system that is compatible with Hadoop. It has the capability to work with any Hadoop supported storage system such as HDFS, S3. Spark uses in-memory computing to improve efficiency. In-memory computation does not save the intermediate output results to disk. Spark also uses caching to handle repetitive queries. Spark is up to 100x times compared to Hadoop. Spark is developed in Scala.
Spark is another Big Data framework. Spark supports In-Memory processing. Hadoop reads and writes data directly from disk thus wasting a significant amount of time in disk I/O. To tackle this scenario Spark stores intermediate results in memory thus reducing disk I/O and increasing speed of processing.
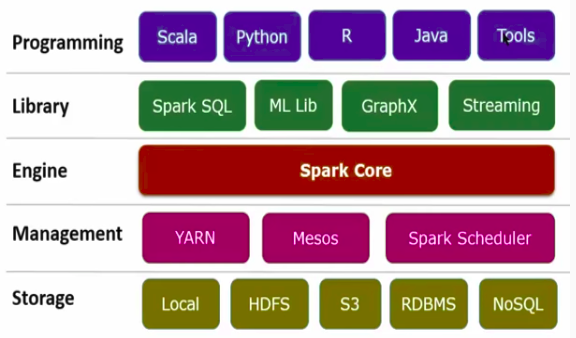
Spark Framework
- Programming: Spark offers Scala, Java, Python, and R.
- Libraries: Spark offers libraries for a very specific task such as Spark SQL, MLLib, GraphX, and Streaming.
- Engine: Spark has its own execution engine “Spark Core” that executes all the spark jobs.
- Management: Spark uses YARN, Mesos, and Spark Scheduler. to manage the resources.
- Storage: It can store and handle data in HDFS, S3, RDBMS, and NoSQL.
Architecture
Spark also uses the master-slave architecture. It has main two entities: Driver and Executors. The driver is a central coordinator (Driver) that communicates with multiple distributed executors.
- The driver is the first process where the main() method executes. driver breaks down a job into various tasks and each task will be assigned or scheduled to a specific executor.
- Executors are also known as workers. Each executor executes the assigned task and takes full charge of completing scheduled tasks. Executor gets a task from the driver and sends the results of each task to the driver. They are instantiated at beginning of cluster creation. The executor handles the RDDs(Resilient Distributed Datasets) using caching and in-memory computation.
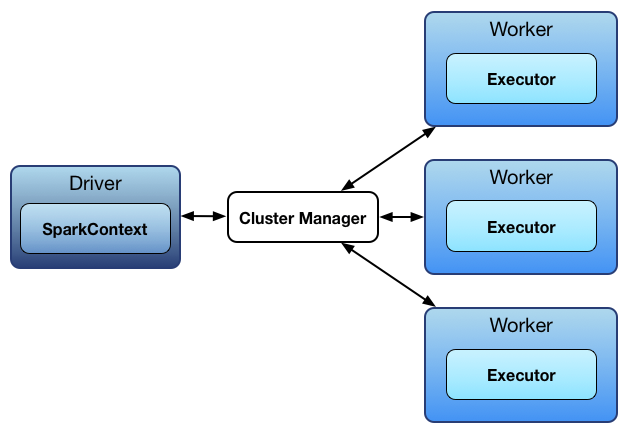
How Spark executes the tasks?
In spark, the application starts with the initialization of SparkContext instance. After this, the driver program gets started and asks for resources from the cluster manager and the cluster manager will launch the executors. The driver sends all the operations to executors. These operations can be actions and transformations over RDDs. Executors perform the task and save the final results.
In case of any executor crash/failure, tasks will be assigned to different executors. Spark has the capability to deal with failure and slow machines. Whenever any node crashes or gets slower then spark launches a speculative copy of the task on another executor or node in the cluster. We can stop the application by using the SparkContext.stop() method. This will terminate all the executors and release the cluster resources.
Resilient Distributed Datasets (RDD)
Spark uses one important data structure to distribute data over the executors in the cluster. This data structure is known as RDD (Resilient Distributed Datasets). RDD is an immutable data structure that can be distributed across the cluster for parallel computation. RDDs can be cached and persisted in memory.
In Map Reduce, data sharing among the nodes is slow because of data replication, serialization, and disk IO operations. Hadoop spends more than 90% of the time read-write operations on HDFS. To address this problem, researchers came with a new key idea of Resilient Distributed Datasets (RDD). RDD supports in-memory computation. In-memory means data is stored in the form of objects across the job and these all operations performed in the RAM. The in-memory concept helped in making 10 to 100 times faster data transfer operations.
RDD Operations
We can perform two types of basic operations on the RDD:
- Transformations: Perform the operation on RDDs and creates new RDDs in the output. It creates a new dataset from an existing one. Transformation operations include map, filter, and join operation.
- Actions: Perform the operation on RDDs and return the results. It returns a value to the driver program. Action operations include count, collect, and save.
“Transformations are lazy, they don’t compute right away. Transformation is only computed when any action is performed.”
Spark Programming Languages
You can execute the task in spark using Scala, Java, Python, and R language. Scala works faster with scala language compared to other languages because Spark is written in Scala. Most of the data scientists prefer Python for doing their tasks. But before using python we need to understand the difference between Python and Scala in Spark.
- Performance: Python is slower in the spark compared to Scala (some say 2x to 10x slower) but it is very helpful for data scientists to get tasks done.
- Ease of use: Python codes are easy to read, and maintain. Also, finding skilled resources is easier in python compared to Scala.
- ML library availability: Python offers some better libraries for data analysis and statistics such as Pandas, NumPy, and SciPy. These libraries are much more mature compared to Scala libraries.
- Supporting Community: Python community is larger compared to the Scala community. This will be helpful for a python programmer to find and discuss the solutions.
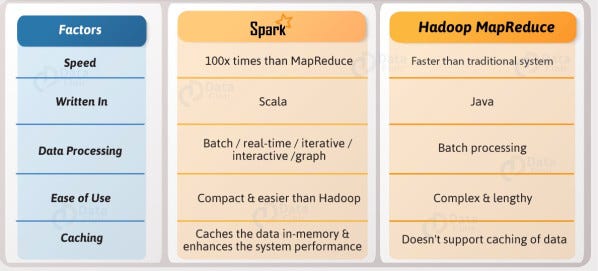
MapReduce Vs Spark
One of the major drawbacks of MapReduce is that it permanently stores the whole dataset on HDFS after executing each task. This operation is very expensive due to data replication. Spark doesn’t write data permanently on disk after each operation. It is an improvement over Mapreduce. Spark uses the in-memory concept for faster operations. This idea is given by Microsoft’s Dryad paper.
The main advantage of spark is that it launches any task faster compared to MapReduce. MapReduce launches JVM for each task while Spark keeps JVM running on each executor so that launching any task will not take much time.
Conclusion
Congratulations, you have made it to the end of this tutorial!
In this tutorial, we will focus on Spark, Spark framework, its architecture, working, Resilient Distributed Datasets, RDD operations, Spark programming language, sand comparison of Spark with MapReduce.
I look forward to hearing any feedback or questions. You can ask a question by leaving a comment, and I will try my best to answer it.


