
Introduction to Hadoop
In this tutorial, we will focus on what is Hadoop, its features, components, job trends, architecture, ecosystem, applications, and disadvantage.
The main objective of any big data platform is to extract the patterns and insights from the large and heterogeneous data for decision making. In this tutorial, we will focus on the basics of Hadoop, its features, components, job trends, architecture, ecosystem, applications, and disadvantages.
How Hadoop developed?
Hadoop was first developed by Doug Cutting and Mike Cafarella at Yahoo In 2005. They developed for handling web crawler project where they need to process billions of web pages for building a search engine. Hadoop is inspired by two research papers from Google: Google File Systems(2003) and MapReduce(2004). Hadoop got his name from the toy elephant. In 2006, yahoo donated Hadoop to apache.
What is Hadoop?
Hadoop is an open-source distributed computing framework for Big Data. Hadoop divides the big datasets into small chunks and executes them in a parallel fashion in a distributed environment. In this distributed system, data processed across nodes or clusters of computers using parallel programming models. It scales processing from single servers to a thousand of multiple machines. Hadoop has the capability of automatic failure detection and handling.
Features
Hadoop has the following features:
- In batch processing, the same types of jobs are executed in groups, or batches and all the required operations are performed in a sequence.
- It is developed for mass-scale computing that can scale from a few computers to thousands of computers.
- It uses the concepts of functional programming for programming.
- It supports several types of data storage structured as well as unstructured.
- It offers automatic failure detection and handling.
Hadoop Components
Hadoop has the following two core components:
- Hadoop Distributed File System (HDFS): It is a distributed file system that stores the data distributed over multiple machines in a cluster. It reduces costs and increases reliability.
- MapReduce: It is a computing model for processing a large dataset in parallel on multiple machines. It can perform the following operations such as filters, sorts, and aggregate operations.
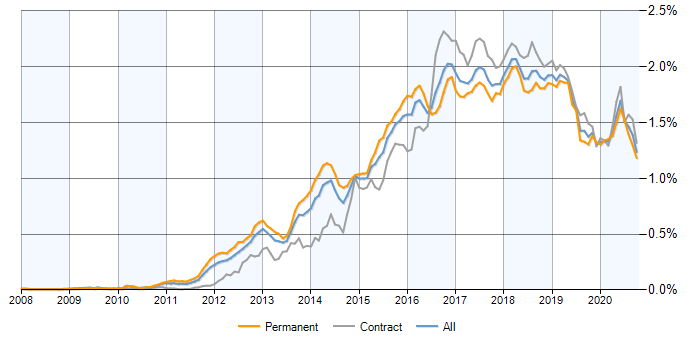
Hadoop Job Trend
After 15 years old technology, Hadoop is quite popular in the Big Data industry and still offers job opportunities. In the last 2–3 years, the number of jobs reduced in Hadoop but the Global Hadoop market prediction said that the market will grow at a CAGR of 33% between 2019 and 2024. What I can suggest to you is that learn some support techniques of Hadoop and Big Data such as Spark, Kafka, etc. These things will help you in landing a promising career in Big Data.
Hadoop Users
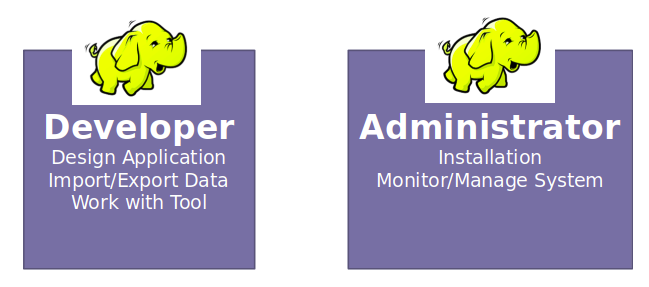
Basic Hadoop Architecture
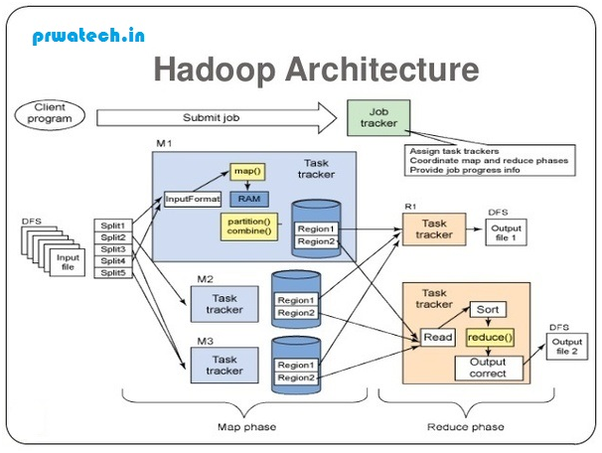
Let’s see a detailed architecture diagram of Hadoop:
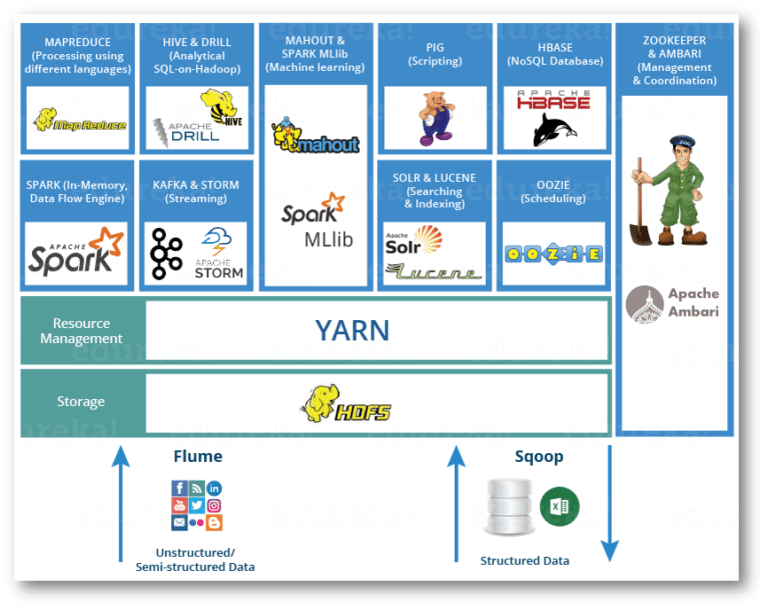
Hadoop Ecosystem
When to use Hadoop?
Hadoop is a standard tool for big data processing. It has the capability to compute large datasets and draw some insights. It is helpful in the aggregation of large datasets because of reducing operations. It is also useful for large scale ETL operations.
When not to use Hadoop?
In real-time Analytics, we need quick results. Hadoop is not suitable for real-time processing because it works batch processing( so data processing is time consuming). Hadoop is not going to replace the existing infrastructures such as MySQL and Oracle. Hadoop is costlier for small datasets.
Hadoop Disadvantages:
- Hadoop uses at least 3 copies of a single data file for data availability and fault tolerance. Big data is already large volume size will and creating 3 replicas that magnify the data size. It will degrade the performance.
- Hadoop is not suitable for real-time processing systems because it consumes more time.
- Privacy and security are the most challenging and critical aspects of the Hadoop environment.
- Hadoop is not efficient for caching.
Hadoop Applications
Hadoop offers the following applications:
- Advertisement: It mines customer behaviors and generates recommendations based on their preferences.
- Search Engines: It crawls data from web pages and creates indexes for searching.
- Information Security: It is used to process large organizational activities and compare it with security policy and identify the breaches and threats.
- Analyze Transactional Data: It analyzes customer transactions and helps retailers to target the promotions and discover customer preferences.
- Churn Analysis: It helps us to analyze why customers are leaving the companies?
Conclusion
Finally, we can say Hadoop is an open-source distributed platform for processing big data efficiently and effectively. In this tutorial, our main focus is an introduction to Hadoop. you have understood what Hadoop is, its features, components, job trends, architecture, ecosystem, applications, and disadvantage. In the next tutorial, we will focus on Hadoop Distributed File Systems(HDFS).


