
Strings in Julia
Strings might seem like too trivial a topic to dedicate a whole article to. But there are merits to
discussing trivialities, first off, it lowers the barrier to entry, tremendously helping beginners. It’s
important for non-beginners as well, because these foundations showcase the philosophy behind a
language. And on that note, we’re starting off a week-long dive into the basics, Julia 101. It’s going
to be targeted at students green to Julia, but shall occasionally include bits that more experienced
practitioners shall also find interesting.
Characters vs Strings
As the name implies, characters refer to a single element of our lexicon, which is Julia’s case is
Unicode(UTF8 encoded). In simple terms, Julia’s Char can essentially contain any symbol that you
can send on Whatsapp. But, Char, true to its namesake, can only one symbol, if you want more,
you go for strings, which again, as their name suggests, are just a string of characters. The
datatype you use for this purpose is String. So, you may be wondering, why to use Char if it’s
functionality is a strict subset of that of String? Well, for two simple reasons, performance, and
style. Following are some toy examples:
julia> "this is a string" # Output below
"this is a string"
julia> 'Ω' #this is a character, output below
'Ω': Unicode U+03A9 (category Lu: Letter, uppercase)
julia> Char(0x0915) #This is another way to construct a character, output below
'क': Unicode U+0915 (category Lo: Letter, other)
julia> 'के' #this is NOT a character, output below
ERROR: syntax: character literal contains multiple characters
Stacktrace:
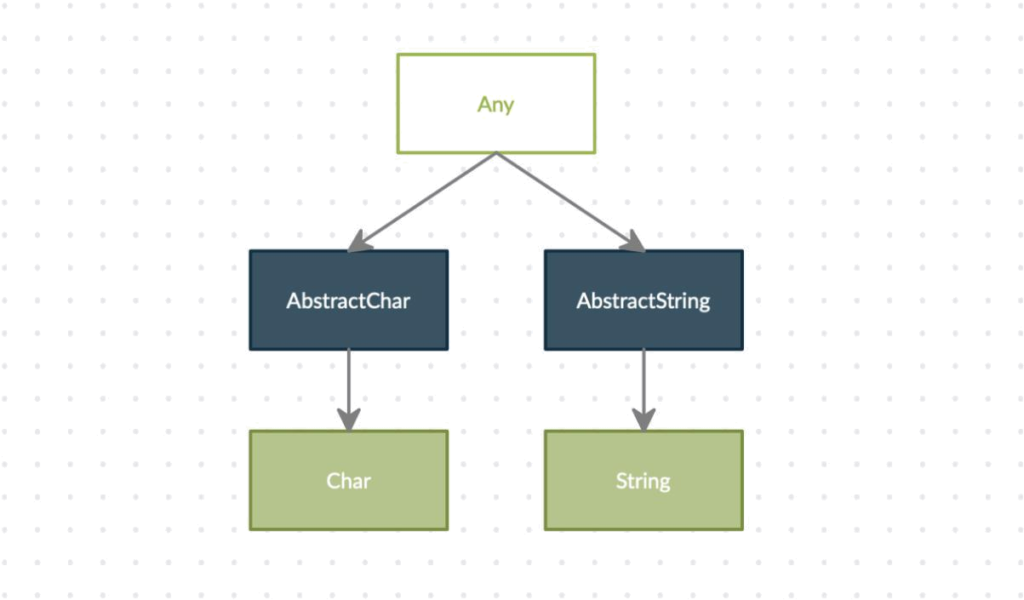
[1] top-level scope at none:1From the point of view of the Julia compiler, characters and strings are not related whatsoever,
both are distinct datatypes with only the trivial ancestor. If you’re not sure what that means, go
check out the previous Julia article on datatypes here.
This is important when doing comparisons, as a bonus, the following example showcases the
julia> 'a'=="a" #output below
false
julia> Char(97)=='a'==Char(0x0061)=='\u0061' #If this seems obscure, read previous article
trueString basics
Moving on, we now talk about strings and operations on them. First of all, you should know that
strings are not implemented as arrays of characters. But, you can treat them like arrays:
julia> MLG="We also have an article on arrays in Julia 😁"
"We also have an article on arrays in Julia 😁"
julia> MLG[1] #This outputs a character as seen below
'W': ASCII/Unicode U+0057 (category Lu: Letter, uppercase)
julia> MLG[end] #This outputs the last character of the string
'😁': Unicode U+1F601 (category So: Symbol, other)
julia> MLG[begin:end-2]# here we use a range to grab all but the last two characters
"We also have an article on arrays in Julia"Do note that when grabbing an element, you get a Char, whereas slicing always gives you a String :
julia> print("MLG[end] is a $(typeof(MLG[end])) whereas MLG[end:end] $(typeof(MLG[end:end])).")
MLG[end] is a Char whereas MLG[end:end] String.
julia> print("Even though they both have the same content; Is $(MLG[end]) distinct from $(MLG[end:end])?")
Even though they both have the same content; Is 😁 distinct from 😁?Now, for the cautionary note, as mentioned earlier, we can happily treat strings like arrays because
they are arrays. Just, strictly speaking, they aren’t arrays of Char ,this is so due to Julia indexing
arrays based on bytes. That is, n th index of an array refers to it’s n th byte. This is all well and good
with fixed-width formats, but Unicode is a variable-byte format, and thus often, characters occupy
multiple bytes.
So, if you’re strictly dealing with characters you know to be in ASCII, even though you’re actually in
Unicode you can go about your business treating strings like arrays of Char and never have any
issues. But, lets see what happens when you deal with non-ASCII Unicode characters:
julia> k="\u0915 ASCII be like 😒"
"क ASCII be like 😒"
julia> k[2]
ERROR: StringIndexError("क ASCII be like 😒", 2)
Stacktrace:
[1] string_index_err(::String, ::Int64) at ./strings/string.jl:12
[2] getindex_continued(::String, ::Int64, ::UInt32) at ./strings/string.jl:220
[3] getindex(::String, ::Int64) at ./strings/string.jl:213
[4] top-level scope at REPL[199]:1But if you’re dealing with non-ASCII characters, you need to be a bit more careful. If you simply
want to find the next valid index:
julia> nextind(k,0)#what's the next valid index after 0?
1
julia> nextind(k,1)#what's the next valid index after 1?
4
julia> nextind(k,4)#what's the next valid index after 4?
5If instead, you want to iterate through each character, then an elegant solution is via using a for
loop. We cover it later in the series, here.
String operations
First things first, how to join strings? pass them all into a constructor, or simpler yet, use
julia> string("Machine","Learning","Geek",'🏁')
"MachineLearningGeek🏁"
julia> "Machine"*"Learning"*"Geek"*'🏁'
"MachineLearningGeek🏁"Next up, how do you compare strings? Just like numbers, but in dictionary order!
julia> "Machine"=="Geek"
false
julia> "Machine"!="Geek"
true
julia> "aa"<"ba"<"bb" #Here the ordering is lexicographical
trueAs is the custom, coup de grâce to string operations is regex. Let’s look at how we’d redact the
digits of a debit card number
julia> cardNumber="3242781928737234"
"3242781928737234"
julia> pattern=r"\d{1,4}(?=(\d{4})+(?!\d))" #The pattern we'll use to regex
r"\d{1,4}(?=(\d{4})+(?!\d))"
julia> replace(cardNumber,pattern=>"XXXX ")
"XXXX XXXX XXXX 7234"And that’s a wrap! Next time we’ll discuss packages.


