
Building Movie Recommender System using Text Similarity
In this tutorial, we will focus on the movie recommender system using the NLP technique.
With the dawn of the internet, utilizing information has become pervasive but the rapid growth of information causes the problem of information overload. In this large amount of information, how to find the right information which meets customer needs. In this context, Recommender System can help us to deal with such huge information. Also, with the increase in user options and rapid change in user preferences, we need some online systems that quickly adapt and recommend the relevant items.
A recommender system computes and suggests the relevant items based on user details, content details, and their interaction logs such as ratings. For example, Netflix is a streaming platform that recommends movies and series and keeps the consumer engaged on their platform. This engagement motivates customers to renew their subscriptions.
Content-based recommender system uses descriptive details products in order to make recommendations. For example, if the user has liked a web series in the past and the feature of that web series comedy genre then Recommender System will recommend the next series or movie based on the same genre. So the system adapts and learns the user behavior and suggests the items based on that behavior. In this article, we are using movie description or overview text to discover similar movies for recommendation using text similarity.
In this tutorial, we are going to cover the following topics:
Loading Dataset
In this tutorial, we will build a movie recommender system using text similarity measures. You can download this dataset from here.
Let’s load the data into pandas dataframe:
# Import pandas for data manipulation
import pandas as pd
# Import TFIDF
from sklearn.feature_extraction.text import TfidfVectorizer
# Import cosine similarity
from sklearn.metrics.pairwise import cosine_similarity
# Read the dataset
movies = pd.read_csv('tmdb_5000_movies.csv')
# Show Top-5 records
movies.head()Output:
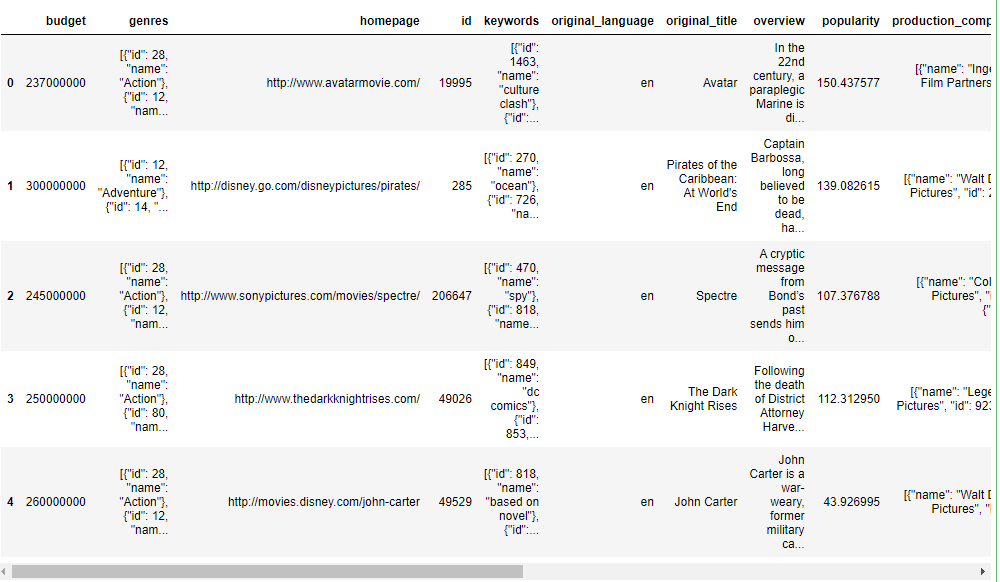
In the above code snippet, we have loaded The Movie Database (TMDb) data in Pandas DataFrame.
Explore Movie Overview Text
In this section, we can explore the text overview of given movies. for doing exploratory analysis, the best way is to use Wordcloud and understand the most frequent words in the overview of the movie.
# Import WordCloud and STOPWORDS
from wordcloud import WordCloud
from wordcloud import STOPWORDS
# Import matplotlib
import matplotlib.pyplot as plt
# Prepare movie overview
paragraph=" ".join(movies.overview.to_list())
# Create stopword list
stopword_list = set(list(STOPWORDS) + ['br',])
# Create WordCloud
word_cloud = WordCloud(width = 1000, height = 800,
background_color ='White',
stopwords = stopword_list,
min_font_size = 14).generate(paragraph)
# Set wordcloud figure size
plt.figure(figsize = (15, 9))
# Show image
plt.imshow(word_cloud)
# Remove Axis
plt.axis("off")
# save word cloud
# plt.savefig('wordcloud.jpeg',bbox_inches='tight')
# show plot
plt.show()
In the above code block, we have imported the wordcloud, stopwords, and matplotlib library. First, we created the combined text of all the movie overview descriptions and created the wordcloud on white background.
Perform Feature Engineering
In the Text Similarity Problems, If we are applying cosine similarity then we have to convert texts into the respective vectors because we directly can’t use text for finding similarity. Let’s create vectors for given movie reviews using the TF-IDF approach.
TF-IDF(Term Frequency-Inverse Document Frequency) normalizes the document term matrix. It is the product of TF and IDF. TF-IDF normalizes the document weights. The higher value of TF-IDF for a word represents a higher occurrence in that document.
tfidf = TfidfVectorizer(analyzer='word',
token_pattern=r'\w{1,}',
ngram_range=(1, 3),
stop_words = 'english')
# Filling NaNs with empty string
movies['overview'] = movies['overview'].fillna('')
# Fitting the TF-IDF on the 'overview' text
tfidf_matrix = tfidf.fit_transform(movies['overview'])
tfidf_matrix.shapeOutput:
(4803, 266025)
In the above code block, Scikit-learn TfidfVectorizer is available for generating the TF-IDF Matrix.
Building Recommender System using Cosine Similarity
Cosine similarity measures the cosine angle between two text vectors. Its value implies that how two documents are related to each other. Cosine similarity can be computed for the non-equal size of text documents.
# Compute the Cosine Similarity
similarity_matrix = cosine_similarity(tfidf_matrix, tfidf_matrix)
# Create a pandas series with movie titles as indices and indices as series values
indices = pd.Series(movies.index, index=movies['original_title']).drop_duplicates()In the above code, we have computed the cosine similarity using the cosine_similarity() method of sklearn.metrics module.
Recommeding Movies based on Similary Movie Overview
Let’s make a forecast using computed cosine similarity on movie description data.
title='The Matrix'
# Get the index corresponding to movie title
index = indices[title]
# Get the cosine similarity scores
similarity_scores = list(enumerate(similarity_matrix[index]))
# Sort the similarity scores in descending order
sorted_similarity_scores = sorted(similarity_scores, key=lambda x: x[1], reverse=True)
# Top-10 most similar movie scores
top_10_movies_scores = sorted_similarity_scores[1:11]
# Get movie indices
top_10_movie_indices=[]
for i in top_10_movies_scores:
top_10_movie_indices.append(i[0])
# Top 10 recommende movie
movies['original_title'].iloc[top_10_movie_indices]Output: 775 Supernova 2088 Pulse 0 Avatar 1281 Hackers 1341 Obitaemyy Ostrov 2996 Commando 4395 The Specials 4231 The Believer 3649 Lovely, Still 354 The Girl with the Dragon Tattoo Name: original_title, dtype: object
In the above code, we have generated the Top-10 movies based on similar movie overview descriptions.
Summary
Congratulations, you have made it to the end of this tutorial!
In the last decade, the use of recommendation systems is increasing rapidly in lots of business ventures such as online retail business, learning, tourism, fashion, and library portals. The recommendation system assists in choosing the right thing from a large number of items by focusing on item features and user profiles.
In this tutorial, we have built the movie recommender system using text similarity.
In upcoming articles, we will write more articles on different recommender systems using Python.


