
Book Recommender System using KNN
In this world of the internet, information is generating and growing rapidly. This huge amount of information will create information overload. People need to make decisions and make choices from available information or options. For example, People want to make a decision which Smartphone should they buy, which course they enroll in, which movie they watch, and which book they buy.
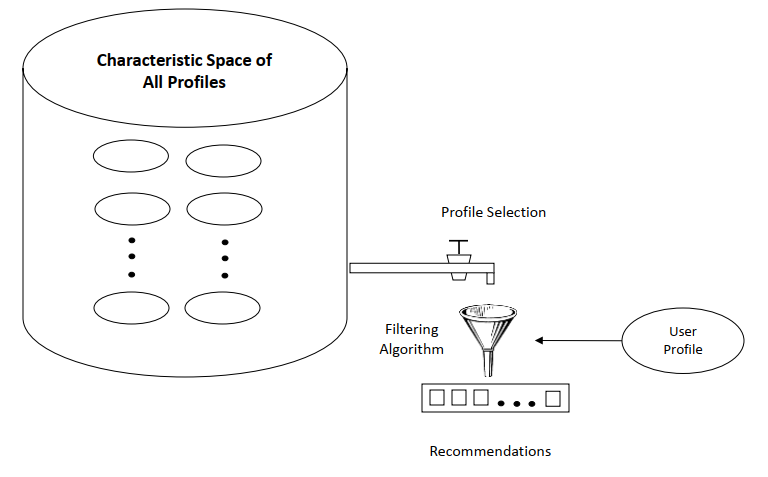
Recommender System is an automatic suggestion system that provides suggestions on things just like your friends, relatives, or neighbors give suggestions. A recommender system will help customers to find interesting things, reduce the number of options, and discover new things. At the same time, it also helps businesses to increase sales, increase user satisfaction and understand user needs. You have also seen youtube where they recommend videos based on your previously watched videos. Netflix recommends related movies based on previously watched movies.
In this tutorial, we are going to cover the following topics:
Functions of Recommeder System
The main functions of the recommender system are:
- It helps user to deal with information overload by filtering recommendations of product.
- It helps businesses to generate more profits by selling more products.
In this article, we will build a Book Recommenders System using KNN.
Collaborative and Content Based Filtering
Collaborative filtering focuses on the ratings of the items given by users. It is based on “Wisdom of the crowd”. It predicts the suggested items based on the taste information from other users i.e. recommendations are from collaborative user ratings. collaborative filtering is used by large organizations such as Amazon and Netflix. It will suffer from cold start problems, sparsity problems, popularity bias, and first starter.
Content-based filtering recommends items to users based on the description of the items and user profile. For example, recommending products based on the textual description, recommending movies based on their textual overview, and recommending books based on associated keywords. It will suffer where content is not well represented by keywords and the problem of indistinguishable items(same set feature items).
Loading the Data
In this tutorial, you will build a book recommender system. You can download this dataset from here.
Let’s load the data into pandas dataframe:
import pandas as pd
# Read Ratings csv file
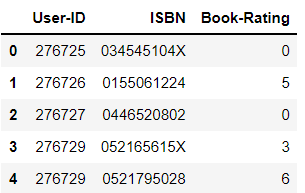
ratings = pd.read_csv("data/Ratings.csv", encoding='latin-1')
# Show top-5 records
ratings.head()Output:
# Read Books csv file
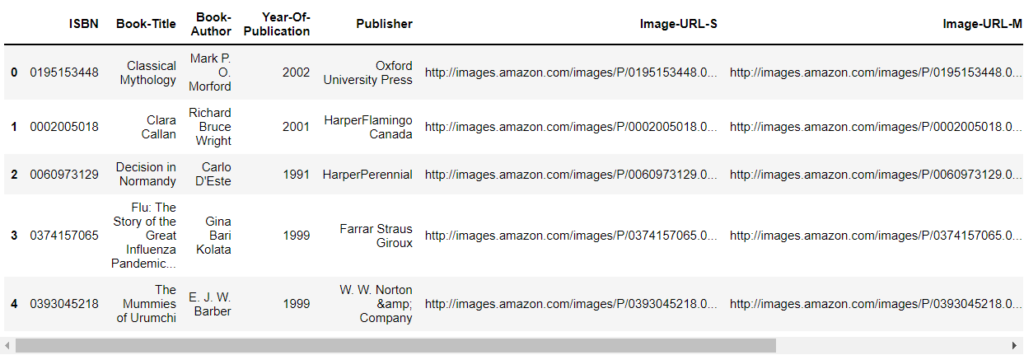
books = pd.read_csv("data/Books.csv", encoding='latin-1')
# Show top-5 records
books.head()Output:
In the above two code snippet, we have loaded the Ratings and Books data in Pandas DataFrame.
Merge the Data
In this section, we will merge the ratings and books’ dataframes based on the ISBN column using merge() function.
# Join ratings and books dataframes
rating_books=pd.merge(ratings,books,on="ISBN")
# Shape of the data
rating_books.shapeOutput: (1031136, 10)
Create Item-User Matrix using pivot_table()
In this section, we will create the pivot table with book-title on the index, user id on the column, and fill values book rating. But before this first, we take a sample(1%) of the whole dataset because this dataset has 1 million records. If we don;t do this it will take a very long time or may cause of memory error on 8 GB Laptop.
# Take 1 % data as sample
rating_books_sample = rating_books.sample(frac=.01, random_state=1)
# Shape of the sample data
rating_books_sample.shapeOutput: (10311, 10)
Let’s create a Pivot table:
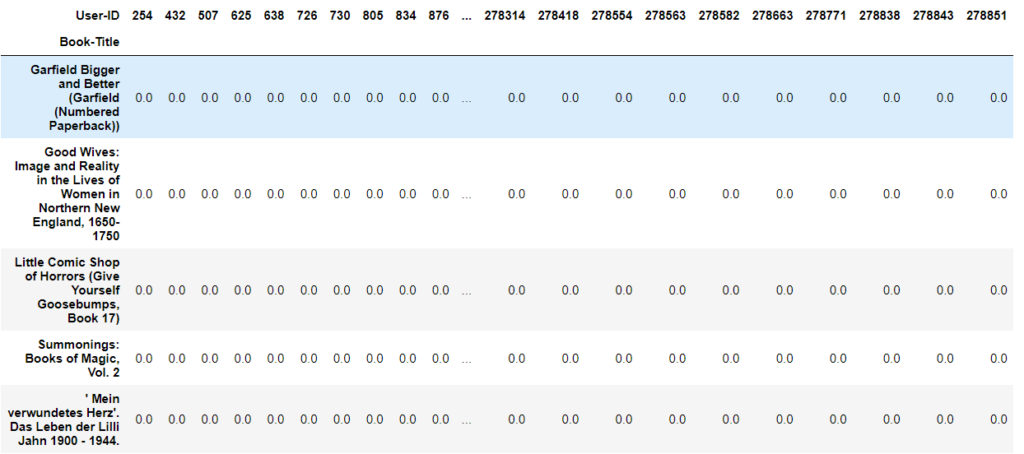
# Create Item-user matrix using pivot_table()
rating_books_pivot = rating_books_sample.pivot_table(index='Book-Title', columns='User-ID', values='Book-Rating').fillna(0)
# Show top-5 records
rating_books_pivot.head()Output:
Build Nearest Neighbour Model
It’s time to create a NearestNeighbours model for recommendations using the Scikit-lean library.
# Import NearestNeighbors
from sklearn.neighbors import NearestNeighbors
# Build NearestNeighbors Object
model_nn = NearestNeighbors(metric='cosine', algorithm='brute', n_neighbors=7, n_jobs=-1)
# Fit the NearestNeighbor
model_nn.fit(rating_books_pivot)Generate Recommendations
Let’s make a forecast using a trained model of NearestNeighbours and generate a list of recommended books.
# Get top 10 nearest neighbors
indices=model_nn.kneighbors(rating_books_pivot.loc[['10 Secrets for Success and Inner Peace']], 10, return_distance=False)
# Print the recommended books
print("Recommended Books:")
print("==================")
for index, value in enumerate(rating_books_pivot.index[indices][0]):
print((index+1),". ",value)Output:
Recommended Books: ================== 1 . 10 Secrets for Success and Inner Peace 2 . Soul Harvest: The World Takes Sides (Left Behind No. 4) 3 . Sophies Choice 4 . Sorcerer's Son 5 . Sorceress of Darshiva (Malloreon (Paperback Random House)) 6 . Sosa : An Autobiography 7 . Soul Among Lions: The Cougar As Peaceful Adversary 8 . Soothing Soaps: For Healthy Skin 9 . Soul Survivor 10 . Souls Belated (Penguin Classics 60s)
In the above output, we can see the list of recommended books.
Issues with KNN Recommender System
Issues with NN-Based Collaborative Filtering
- Popularity Bias: KNN Based Collaborative Recommender Systems is biased towards books those have the most user ratings.
- Cold Start problem: When a new movie is added to the list, it has a lot less user interaction and thus will rarely occur as a recommendation.
- scalability issue: The issue of managing a movie-user dataset matrix as the count of users and movies increase, since the matrix that we will deal with will have 90% of the values being 0. Storing such a sparse matrix wastes space when the database accommodates millions of users and movies.
Summary
Congratulations, you have made it to the end of this tutorial!
In this tutorial, we have built the recommender system using the K-Nearest Neighbors algorithm.
In upcoming articles, we will write more articles on different recommender systems using Python.


