
Text Summarization using Python
Learn how to summarize text using extractive summarization techniques such as TextRank, LexRank, LSA, and KL-Divergence.
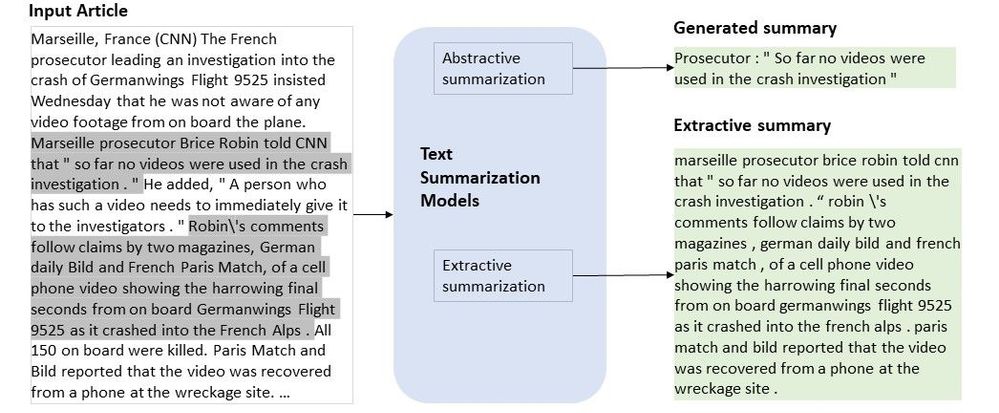
A summary is a small piece of text that covers key points and conveys the exact meaning of the original document. Text summarization is a method for concluding a document into a few sentences. It can be performed in two ways:
- Abstractive Text Summarization
- Extractive Text Summarization
The abstractive method produces a summary with new and innovative words, phrases, and sentences. The extractive method will take the same words, phrases, and sentences from the original summary. Extractive methods can be considered as important sentence selection in the given text. In this tutorial, our main focus is on extractive summarization techniques such as Text Rank, Lex Rank, LSA, and KL Divergence.
Text Rank
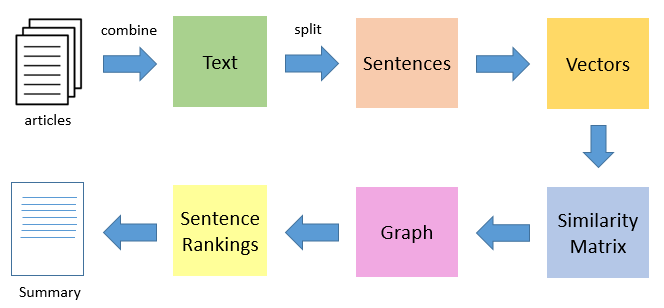
Text Rank is a kind of graph-based ranking algorithm used for recommendation purposes. TextRank is used in various applications where text sentences are involved. It worked on the ranking of text sentences and recursively computed based on information available in the entire text.
TextRank builds the graph related to the text. In a graph, each sentence is considered as vertex and each vertex is linked to the other vertex. These vertices cast a vote for another vertex. The importance of each vertex is defined by the higher number of votes. This importance is Here goal is to rank the sentences and this rank.
TextRank works in the following steps:
1. Tokenize documents into sentences.
2. Preprocess each sentence in the document.
3. Count key phrases and normalize them or produce TFIDF Matrix, you can also use any kind of vectorization such as spacy vectors.
4. Calculate the Jaccard Similarity between sentences and key phrases.
5. Rank the sentences with higher significance.
TextRank is a graph-based algorithm, easy to understand and implement. Its results are less semantic. Let’s do hands-on using gensim and sumy package.
Using Gensim Package
gensim package is used for natural language processing and information retrievals tasks such as topic modeling, document indexing, wro2vec, and similarity retrieval. Here we are using it for text summarization.
Install gensim using pip:
pip install gensim# Original text
text="""A vaccine for the coronavirus will likely be ready by early 2021 but rolling it out safely across India’s
1.3 billion people will be the country’s biggest challenge in fighting its surging epidemic, a leading vaccine
scientist told Bloomberg.India, which is host to some of the front-runner vaccine clinical trials, currently has
no local infrastructure in place to go beyond immunizing babies and pregnant women, said Gagandeep Kang, professor
of microbiology at the Vellore-based Christian Medical College and a member of the WHO’s Global Advisory Committee
on Vaccine Safety.The timing of the vaccine is a contentious subject around the world. In the U.S.,
President Donald Trump has contradicted a top administration health expert by saying a vaccine would be available
by October. In India, Prime Minister Narendra Modi’s government had promised an indigenous vaccine as early
as mid-August, a claim the government and its apex medical research body has since walked back.
"""
from gensim.summarization.summarizer import summarize
# Summarize text using gensim
gen_summary=summarize(text)
print(gen_summary)Output:
In India, Prime Minister Narendra Modi’s government had promised an indigenous vaccine as early as mid-August, a claim the government and its apex medical research body has since walked back.Using sumy Package
sumy is an automatic text summarized library that is a simple library and easy to use. It has implemented various summarization algorithms such as TextRank, Luhn, Edmundson, LSA, LexRank, KL-Sum, SumBasic, and Reduction. Let’s see an example of a TextRank algorithm.
Install sumy using pip:
pip install sumy# Load Packages
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
# Creating text parser using tokenization
parser = PlaintextParser.from_string(text,Tokenizer("english"))
from sumy.summarizers.text_rank import TextRankSummarizer
# Summarize using sumy TextRank
summarizer = TextRankSummarizer()
summary =summarizer(parser.document,2)
text_summary=""
for sentence in summary:
text_summary+=str(sentence)
print(text_summary)Output:
A vaccine for the coronavirus will likely be ready by early 2021 but rolling it out safely across India’s 1.3 billion people will be the country’s biggest challenge in fighting its surging epidemic, a leading vaccine scientist told Bloomberg.India, which is host to some of the front-runner vaccine clinical trials, currently has no local infrastructure in place to go beyond immunizing babies and pregnant women, said Gagandeep Kang, professor of microbiology at the Vellore-based Christian Medical College and a member of the WHO’s Global Advisory Committee on Vaccine Safety.Lex Rank
LexRank is another graph-based method for summarization. It is similar to TextRank and unsupervised in nature. LexRank uses Cosine similarity instead of Jaccard Similarity between two sentences. This similarity score will be used to build a weighted graph for all the sentences in the document. LexRank also takes care of the chosen top most sentences will not too similar to each other.
LexRank is a graph-based algorithm, easy to understand and implement. Its results are less semantic.
from sumy.summarizers.lex_rank import LexRankSummarizer
summarizer_lex = LexRankSummarizer()
# Summarize using sumy LexRank
summary= summarizer_lex(parser.document, 2)
lex_summary=""
for sentence in summary:
lex_summary+=str(sentence)
print(lex_summary)Output: A vaccine for the coronavirus will likely be ready by early 2021 but rolling it out safely across India’s 1.3 billion people will be the country’s biggest challenge in fighting its surging epidemic, a leading vaccine scientist told Bloomberg.India, which is host to some of the front-runner vaccine clinical trials, currently has no local infrastructure in place to go beyond immunizing babies and pregnant women, said Gagandeep Kang, professor of microbiology at the Vellore-based Christian Medical College and a member of the WHO’s Global Advisory Committee on Vaccine Safety.
LSA
Latent Semantic Analysis is based on Singular value decomposition(SVD). It reduces the data into lower-dimensional space. It performs spatial decomposition and captures information in a singular vector and the magnitude of so singular vector will represent the importance.
LSA has the capability to extract semantically related sentences but its computation is complex.
from sumy.summarizers.lsa import LsaSummarizer
summarizer_lsa = LsaSummarizer()
# Summarize using sumy LSA
summary =summarizer_lsa(parser.document,2)
lsa_summary=""
for sentence in summary:
lsa_summary+=str(sentence)
print(lsa_summary)Output: A vaccine for the coronavirus will likely be ready by early 2021 but rolling it out safely across India’s 1.3 billion people will be the country’s biggest challenge in fighting its surging epidemic, a leading vaccine scientist told Bloomberg.India, which is host to some of the front-runner vaccine clinical trials, currently has no local infrastructure in place to go beyond immunizing babies and pregnant women, said Gagandeep Kang, professor of microbiology at the Vellore-based Christian Medical College and a member of the WHO’s Global Advisory Committee on Vaccine Safety.
KL Divergence
KL-Divergence calculates the difference between two probability distributions. Probability distribution P to an arbitrary probability distribution Q. It measures between the unigram probability distributions learned from seen document set p(w/R) and new document set q(w/N).
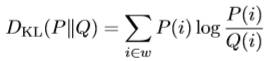
KL divergence approach takes a matrix of the KLD value of sentences from the input document. We select the sentences with lower KLD values for creating a summary. KL divergence generates good summaries that are intuitively similar to the original document. Let’s see hands-on using sumy package.
from sumy.summarizers.kl import KLSummarizer
summarizer_kl = KLSummarizer()
# Summarize using sumy KL Divergence
summary =summarizer_kl(parser.document,2)
kl_summary=""
for sentence in summary:
kl_summary+=str(sentence)
print(kl_summary)Output:The timing of the vaccine is a contentious subject around the world.In the U.S., President Donald Trump has contradicted a top administration health expert by saying a vaccine would be available by October.
Summary
In this tutorial, we have seen Text summarization, its types, and some of the extractive algorithms such as TextRank, LexRank, LSA, and KL Divergence. we have performed hands-on on these algorithms using sumy package. Also, we have used gensim module for the TextRank algorithm. In this summarization, we can’t say which algorithm is working better than others because in some cases one algorithm will show the better and in some other cases other algorithms will show better results. For a more intuitive summary, I will recommend you can try with a hybrid approach or go for abstractive summarization.


