Activation Functions
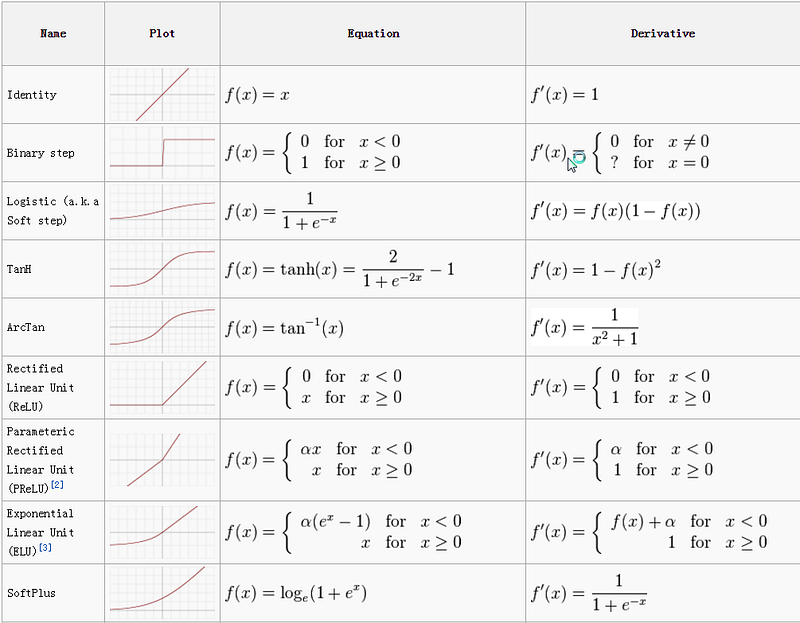
The activation function defines the output of a neuron in terms of the induced local field. Activation functions are a single line of code that gives the neural networks non-linearity and expressiveness. There are many activation functions such as Identity function, Step function, Sigmoid function, Tanh, ReLU, Leaky ReLU, Parametric ReLU, and Softmax function. We can see some of them in the following table:
In this tutorial, we are going to cover the following topics:
Identity Function
The identity function is a function that maps input to the same output value. It is a linear operator in vector space. Also, a known straight-line function where activation is proportional to the input. The simplest example of a linear activation function is a linear equation.
f(x) = a * x,where a ∈ R
The major problem with such kind of linear function it cannot handle complex scenarios.
Binary Step Function
In Binary Step Function, if the value of Y is above a certain value known as the threshold, the output is True(or activated) and if it’s less than the threshold then the output is false (or not activated). It is very useful in the classifier.
The main problem with the binary step function is zero gradients or it is not differentiable at zero. It cannot update the gradient in backpropagation. It only works with binary class problems because it maps to only two categories 0 and 1.
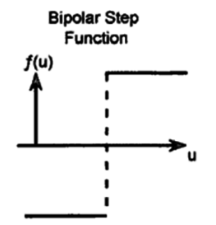
Bipolar Step Function
In the Bipolar Step Function, if the value of Y is above a certain value known as the threshold, the output is +1and if it’s less than the threshold then the output is -1. It has bipolar outputs (+1 to -1). It can be utilized in single-layer networks.
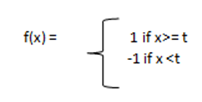
Sigmoid Function
It is also called S-shaped functions. Logistic and hyperbolic tangent functions are commonly used in sigmoid functions. There are two types of sigmoid functions.
- Binary Sigmoid function (or Logistic function)
- Bipolar Sigmoid function (or Hyperbolic Tangent Function or Tanh)
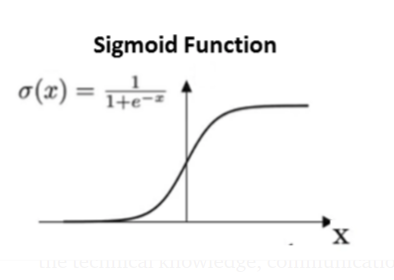
Binary Sigmoid Function
Binary Sigmoid Function or Sigmoid function is a logistic function where the output values are either binary or vary from 0 to 1. It is differentiable, non-linear, and produces non-binary activations But the problem with Sigmoid is the vanishing gradients. Also, sigmoid activation is not a zero-centric function.
Hyperbolic Tangent Function or Tanh
Hyperbolic Tangent Function or Tanh is a logistic function where the output value varies from -1 to 1. Also known as Bipolar Sigmoid Function. The output of Tanh centers around 0 and sigmoid’s around 0.5. Tanh Convergence is usually faster if the average of each input variable over the training set is close to zero.
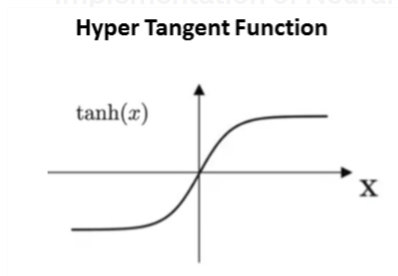
When you struggle to quickly find the local or global minimum, in such case Tanh can be helpful in faster convergence. The derivatives of Tanh are larger than Sigmoid that causes faster optimization of the cost function. Tanh suffered from vanishing gradient problems.
ReLu
ReLu stands for the rectified linear unit (ReLU). It is the most used activation function in the world. It output 0 for negative values of x. This is also known as a ramp function. The name of the ramp function is derived from the appearance of its graph.
ReLu(Rectified Linear Unit) is like a linearity switch. If you don’t need it, you “switch” it off. If you need it, you “switch” it on. ReLu avoids the problem of vanishing gradient. ReLu also provides the benefit of sparsity and sigmoids result in dense representations. Sparse representations are more useful than dense representations.
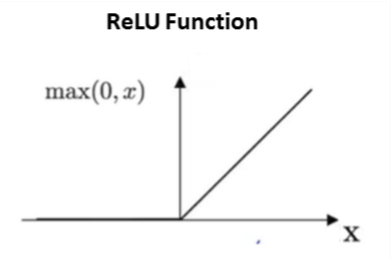
The main problem with ReLU is, it is not differentiable at 0 and may result in exploding gradients.
Leaky ReLU
The main problem of ReLU is, it is not differentiable at 0 and may result in exploding gradients. To resolve this problem Leaky ReLu was introduced that is differentiable at 0. It provides small negative values when input is less than 0. The main problem with Leaky ReLu is not offering consistent predictions in terms of negative data.

Parametric ReLU
PReLU (Parametric ReLU) overcome the dying ReLU problem and Leaky ReLU inconsistent predictions for negative input values. The core idea behind the Parametric ReLU is to make the coefficient of leakage into a parameter that gets learned.
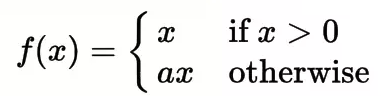

Softmax Function
The softmax function is typically used on the output layer for multi-class classification problems. It provides the probability distribution of possible outcomes of the network.
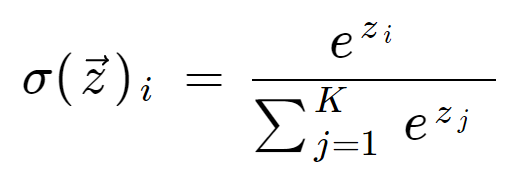
Summary
In conclusion, we can say in deep learning problems, ReLu is used on hidden layers and sigmoid/softmax on the output layer. Sigmoid is used for binary classification, and Softmax is used for multi-class classification problems.
In this tutorial, we have discussed various activation functions, types of activation functions such as Identity function, Step function, Sigmoid function, Tanh, ReLU, Leaky ReLU, Parametric ReLU, and Softmax function. We have discussed the pros and cons of various activation functions. Also, you have understood, how to decide which activation funciton to use?


