
Cross-Validation in scikit-learn
Cross-validation is a statistical method used in Machine Learning for estimating the performance of models. It is very important to know how the model will work on unseen data. The situation of overfitting will cause the model to work perfectly on the training data, but the model loses stability when tested on unknown data. For this purpose, we must ensure that the model learns optimal parameters and gets correct patterns from the training data. This is done using cross-validation.
The cross-validation technique splits the whole data several times into different train sets and test sets and then returns the mean value of the prediction scores for all sets. The model is trained on a subset of data and then tested on the complementary subset of data. This process is repeated several times. Thus, the steps involved in cross-validation are:
- A portion of the data-set is reserved
- The model is trained on the remaining data
- The reserved portion (validation set) is used to test and validate the model.
Some of the common methods of cross-validation are:
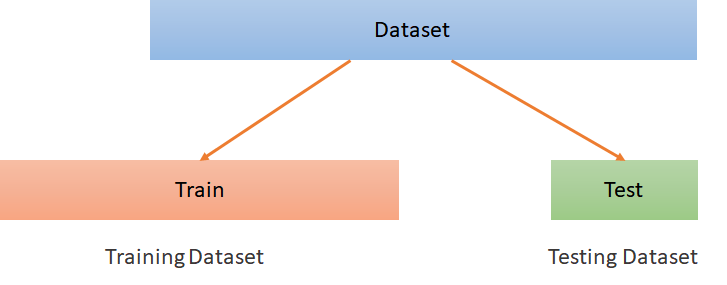
Holdout Method
In this, method the entire dataset is split into two parts – the training dataset and the testing dataset. The data is randomly shuffled and then split. The model is trained on the training dataset and then tested on the testing dataset.
Leave-one-out cross-validation
In the Leave-one-out cross-validation method, training is performed on the whole dataset except one data point on which it is tested. The algorithm then iterates for each data points validating them. The time complexity of this algorithm is huge
K-fold cross-validation
In the K-fold cross-validation method, the data randomly split into k subsets (or folds). For each fold in the dataset, the model is built on (k – 1) folds of the dataset. The model is then tested for the kth fold. This process is repeated until each of the k-folds has become the testing set. An example of k=5:

Stratified k-fold cross-validation
Stratification is the process in which the data is rearranged in such a way that each fold is a good representative of the whole data. This is exactly what is done in the stratified k-folds method.
Python Example
In Python, Cross-validation can be performed using the scikit-learn library. Here, we will work with the sklearn’s wine dataset.
The first step is to load the dataset:
| from sklearn.datasets import load_wine wine = load_wine() |
This is a simple multi-class classification dataset for wine recognition. It has three classes and the number of instances is equal to 178. It has 13 attributes.
In scikit-learn, the simple holdout method can be performed by randomly splitting the dataset into training and test sets using the train_test_split function, as:
| from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(wine.data, wine.target, test_size=0.3, random_state=0) |
This splits the wine dataset into training and test sets in a ratio of 70:30.
We can have a look at the shape of training and testing variables:
| print(x_train.shape) print(y_train.shape) |
Output:
| (124, 13) (124,) |
| print(x_test.shape) print(y_test.shape) |
Output:
| (54, 13) (54,) |
Now let’s create a model with SVM classifier, as:
| from sklearn import svm model = svm.SVC(kernel=’linear’, C=50) |
For the load_wine dataset, we will need SVM’s linear kernel.
Cross-validation can be used on it by calling sklearn’s cross_val_score function on the estimator and the dataset. This can be done as:
| from sklearn.model_selection import cross_val_score cv_scores = cross_val_score(model, wine.data, wine.target, cv=5) print(cv_scores) |
This is how the estimated accuracy of the model on the dataset is calculated – by splitting the data into train and test, fitting a model, and computing the score cv number of consecutive times, with different splits each time. Here cv=5. The output of the above code is:
| [0.88888889 0.97222222 0.94444444 1. 1. ] |
The mean of the above scores data would give the estimated accuracy of the model. We can compute it as:
| import numpy as np print(np.mean(cv_scores)) |
Output:
| 0.961111111111111 |
If the cv argument of the cross_val_score function takes an integer, then the cross_val_score uses the KFold cross-validation or StratifiedKFold method by default. Other cross-validation methods can also be used by passing a cross-validation iterator.
K-fold cross-validation can also be performed by using the KFold function from sklearn.model_selection. Similarly, sklearn also provides separate functionalities for Stratified KFold, Leave-one-out cross-validation, and other methods.
Summary
In this article, we looked at Cross-Validation in scikit-learn. In the next article, we will focus on Grid Search in scikit learn.


