
Feature Scaling: MinMax, Standard and Robust Scaler
Feature Scaling is performed during the Data Preprocessing step. Also known as normalization, it is a method that is used to standardize the range of features of data. Most of the Machine Learning algorithms (for example, Linear Regression) give a better performance when numerical input variables (i.e., numerical features) are scaled to a standard range.
Feature Scaling is important as the scale of the input variables of the data can have varying scales. Python’s sklearn library provides a lot of scalers such as MinMax Scaler, Standard Scaler, and Robust Scaler.
MinMax Scaler
MinMax Scaler is one of the most popular scaling algorithms. It transforms features by scaling each feature to a given range, which is generally [0,1], or [-1,-1] in case of negative values.
For each feature, the MinMax Scaler follows the formula:
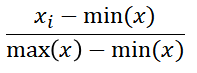
It subtracts the mean of the column from each value and then divides by the range, i.e, max(x)-min(x).
This scaling algorithm works very well in cases where the standard deviation is very small, or in cases which don’t have Gaussian distribution.
Let’s look at an example of MinMax Scaler in Python. Consider, the following data:
| data = [[0,5],[2,13],[-3,7],[1,-4],[6,0]] |
Now, let’s scale this data using sklearn’s MinMax Scaler:
| from sklearn.preprocessing import MinMaxScaler mms = MinMaxScaler().fit(data) print(mms.transform(data)) |
Output:
| [[0.33333333 0.52941176] [0.55555556 1. ] [0. 0.64705882] [0.44444444 0. ] [1. 0.23529412]] |
We can see that the data points have been scaled to values between 0 and 1.
We can also modify the code to scale the values between other range, such as [-2,-2], as:
| mms = MinMaxScaler(feature_range=(-2,2)).fit(data) print(mms.transform(data)) |
Output:
| [[-0.66666667 0.11764706] [ 0.22222222 2. ] [-2. 0.58823529] [-0.22222222 -2. ] [ 2. -1.05882353]] |
Standard Scaler
Standard Scaler follows the Standard Normal Distribution, i.e., it assumes a normal distribution for data within each feature. The scaling makes the distribution centered around 0, with a standard deviation of 1 and the mean removed.
For a data sample x, its score for Standard Scaler is calculated as:
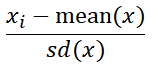
Where sd is the standard deviation of x.
Consider the same previous data:
| data = [[0,5],[2,13],[-3,7],[1,-4],[6,0]] |
Now, let’s scale this data using sklearn’s Standard Scaler:
| from sklearn.preprocessing import StandardScaler ss = StandardScaler().fit(data) print(ss.transform(data)) |
Output:
| [[-0.41015156 0.13687718] [ 0.27343437 1.505649 ] [-1.43553045 0.47907014] [-0.06835859 -1.40299112] [ 1.64060622 -0.71860521]] |
Let’s take another example, a more properly distributed data for this case:
| data = [[0,0],[0,1],[1,0],[1,1]] |
Fit Standard Scaler onto this data:
| from sklearn.preprocessing import StandardScaler ss = StandardScaler().fit(data) |
We can see the mean value, as:
| print(ss.mean_) |
Output:
| [0.5 0.5] |
Now apply the transformation:
| print(ss.transform(data)) |
Output:
| [[-1. -1.] [-1. 1.] [ 1. -1.] [ 1. 1.]] |
Robust Scaler
Robust Scaler algorithms scale features that are robust to outliers. The method it follows is almost similar to the MinMax Scaler but it uses the interquartile range (rather than the min-max used in MinMax Scaler). The median and scales of the data are removed by this scaling algorithm according to the quantile range.
It, thus, follows the following formula:
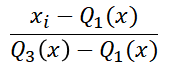
Where Q1 is the 1st quartile, and Q3 is the third quartile.
Let’s see the effect of applying the Robust Scaler on the original data:
| data = [[0,5],[2,13],[-3,7],[1,-4],[6,0]] from sklearn.preprocessing import RobustScaler rs = RobustScaler().fit(data) print(rs.transform(data)) |
Output:
| [[-0.5 0. ] [ 0.5 1.14285714] [-2. 0.28571429] [ 0. -1.28571429] [ 2.5 -0.71428571]] |
Robust Scaler uses the Inter Quartile Range by default, which is the range between the 1st quartile and the 3rd quartile. The quantile range can also be manually specified by using the quantile_range parameter, as:
| rs = RobustScaler(quantile_range = (0.1,0.9)).fit(data) print(rs.transform(data)) |
Output:
| [[-10.41666667 0. ] [ 10.41666667 62.5 ] [-41.66666667 15.625 ] [ 0. -70.3125 ] [ 52.08333333 -39.0625 ]] |
Summary
In this article, we looked at Feature Scaling, and different scalers such as MinMax, Standard, and Robust Scaler. In the next article, we will focus on Cross-Validation in scikit learn.


