
XGBoost Algorithm using Python
XGBoost is one of the most popular boosting algorithms. It is well known to arrive at better solutions as compared to other Machine Learning Algorithms, for both classification and regression tasks.
XGBoost or Extreme Gradient Boosting is an open-source library. Its original codebase is in C++, but the library is combined with Python interface. It helps us achieve a comparatively high-performance implementation of gradient boosted decision trees, can do parallel computations and is easy to implement.
The Boosting technique trains models serial-wise, with every new learning model trained to correct the errors made by its predecessors. In Gradient Boosting, we try to optimize the loss function of the previous learning model by adding a new adaptive model that combines weak learning models. This reduces the loss function. The technique, thus, controls the learning rate and reduces variance by introducing randomness. This performance can be improved even further by using XGBoost.
The objective function of the XGBoost algorithm is a sum of a specific loss function evaluated over all the predictions and the sum of regularization term for all predictors, as:
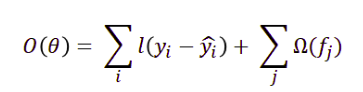
Example in Python
Let’s get started with Python’s XGBoost library. The first step is to install it. This can be easily done with pip command:
| pip install xgboost |
Now, we need a dataset to work with XGBoost. For this article, we will use the wine dataset from sklearn.datasets.load_wine. This is done as:
| from sklearn.datasets import load_wine wine = load_wine() x = wine.data y = wine.target |
This is a simple multi-class classification dataset for wine recognition. It has three classes and the number of instances is equal to 178. It has 13 attributes:
Now, let’s split the data into training data testing data. This is done as:
| from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2) |
Next, we need to create the Xgboost specific DMatrix data format. This is done as:
| import xgboost as xgb dtrain = xgb.DMatrix(x_train, label=y_train) dtest = xgb.DMatrix(x_test, label=y_test) |
Now to get the XGBoost working, we need to set the parameters for xgboost algorithm. Let’s set some parameters for our model, as:
| param = { ‘objective’: ‘multi:softprob’, ‘eta’: 0.4, ‘max_depth’: 3, ‘gamma’: 1.0, ‘num_class’: 3 } |
objective is the loss function used, while num_class is the number of classes in the dataset. In our case, it is equal to 3. max_depth is the maximum depth of the decision tree. eta is the learning rate, which is the step size shrinkage. It is used in the update to prevent overfitting. gamma is the minimum loss reduction that is required to make a further partition on a leaf node of the decision tree.
Now, let’s train our model using XGBoost:
| model = xgb.train(param, dtrain, 20) |
20 is the number of training iterations.
The model can be tested as:
| import numpy as np y_pred = model.predict(dtest) predicts = np.asarray([np.argmax(val) for val in y_pred]) |
Let’s look at the accuracy of our predictions:
| from sklearn.metrics import accuracy_score acc = accuracy_score(y_test, predicts) print(“Accuracy = {}”.format(acc)) |
Output:
| Accuracy = 0.9444444444444444 |
This is a quite good value of accuracy for this dataset.
Summary
In this article, we looked at XGBoost Algorithm using Python. In the next article, we will focus on Feature Scaling: MinMax, Standard, and Robust Scaler.

