Text Similarity Measures
In this tutorial, we will focus on text similarity measures such as Jaccard and Cosine Similarity. Also, learn how to create a small search engine.
Text similarity is used to discover the most similar texts. It used to discover similar documents such as finding documents on any search engine such as Google. We can also use text similarity in document recommendations. Some Q&A websites such as Quora and StackOverflow can also use text similarity to find similar questions. Let’s see the text similarity measures.
In this tutorial, we are going to cover the following topics:
Jaccard Similarity
Jaccard Similarity is the ratio of common words to total unique words or we can say the intersection of words to the union of words in both the documents. it scores range between 0–1. 1 represents the higher similarity while 0 represents the no similarity. Let’s see the formula of Jaccard similarity:
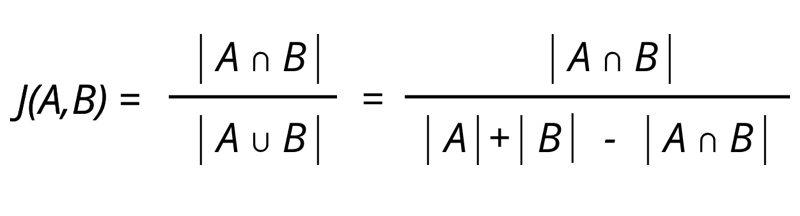
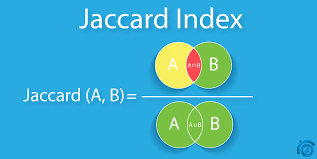
Jaccard similarity considers only the unique set of words for each sentence and doesn’t give importance to the duplication of words. Lets see the implementation of Jaccard Simialrity in Python:
# documents
doc1, doc2='I like dogs.', 'I hate dogs.'
# Split the documents and create tokens
doc1_tokens=set(doc1.lower().split())
doc2_tokens=set(doc2.lower().split())
#Print the tokens
print(doc1_tokens,doc2_tokens)
# Calculate the Jaccard Similarity
jaccard_similarity= len(doc1_tokens.intersection(doc2_tokens))/len(doc1_tokens.union(doc2_tokens))
# Print the Jaccard Simialrity score
print(jaccard_similarity)Output: {‘like’, ‘i’, ‘dogs.’} {‘hate’, ‘i’, ‘dogs.’}
0.5
Cosine Similarity
Cosine similarity measures the cosine of the angle between two vectors. Here vectors can be the bag of words, TF-IDF, or Doc2vec. Let’s the formula of Cosine Similarity:
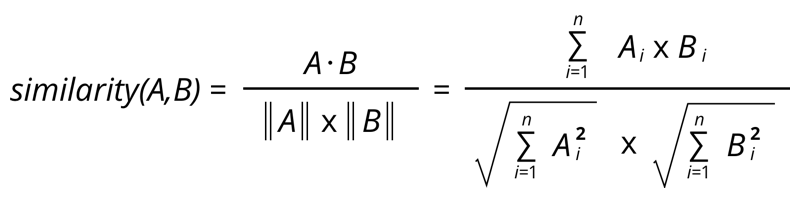
Cosine similarity is best suitable for where repeated words are more important and can work on any size of the document. Let’s see the implementation of Cosine Similarity in Python using TF-IDF vector of Scikit-learn:
# Let's import text feature extraction TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
# Import Cosien Similarity metric
from sklearn.metrics.pairwise import cosine_similarity
docs=['I like dogs.', 'I hate dogs.']
# Create TFidfVectorizer
tfidf= TfidfVectorizer()
# Fit and transform the documents
tfidf_vector = tfidf.fit_transform(docs)
# Compute cosine similarity
cosine_sim=cosine_similarity(tfidf_vector, tfidf_vector)
# Print the cosine similarity
print(cosine_sim)Output: [[1. 0.33609693]
[0.33609693 1. ]]
Cosine Similarity using Spacy
We can also use cosine using Spacy similarity method:
import en_core_web_sm
nlp = en_core_web_sm.load()
## try medium or large spacy english models
doc1 = nlp("I like apples.")
doc2 = nlp("I like oranges.")
# cosine similarity
doc1.similarity(doc2) Output: 0.880
Cosine Similarity using Scipy
We can also implement using Scipy:
from scipy import spatial
# Document Vectorization
doc1, doc2 = nlp('I like apples.').vector, nlp('I like oranges.').vector
# Cosine Similarity
result = 1 - spatial.distance.cosine(doc1, doc2)
print(result)Output: 0.94949
Let’s create a search engine using Text Similarity measures
Let’s create a search engine for finding the most similar sentence using Cosine Similarity. In this search engine, we find thje similar sentences for the given input query.
import en_core_web_sm
from numpy import dot
from numpy.linalg import norm
nlp = en_core_web_sm.load()
# Prepare dataset
doc_list=['I love this sandwich.',
'this is an amazing place!',
'I feel very good about these beers.',
'this is my best work.',
'what an awesome view',
'I do not like this restaurant',
'I am tired of this stuff.',
"I can't deal with this",
'he is my sworn enemy!',
'my boss is horrible.',
'I hate this sandwich.']
# user input
query=input()
# similarity score
sim_scores=[]
# Vectorize input query
q_vector=nlp(query).vector
for doc in doc_list:
# Vectorize document
doc_vector=nlp(doc).vector
# Cosine Similarity
cos_sim = dot(q_vector, doc_vector)/(norm(q_vector)*norm(doc_vector))
# append the score
sim_scores.append(cos_sim)
# most similar
most_similar=doc_list[sim_scores.index(max(sim_scores))]
print("\nMost Similar:\n",most_similar)
# sorting most similar sentences
top_index=list(np.argsort(sim_scores)[-5:])
top_index.reverse()
print("\nMost Similar Documents:\n")
for i in top_index:
print(doc_list[i])Output: I like pizza
Most Similar:
I am tired of this stuff.
Most Similar Documents:
I am tired of this stuff.
I love this sandwich.
what an awesome view
my boss is horrible.
I do not like this restaurant
Summary
Congratulations, you have made it to the end of this tutorial!
In this article, we have learned text similarity measures such as Jaccard and Cosine Similarity. We have also created one small search engine that finds similar sentences for the given input query. Of course, this is just the beginning, and there’s a lot more that we can do using Text Similarity Measures in Information Retrieval and Text Mining.