
AdaBoost Classifier in Python
Understand the ensemble approach, working of the AdaBoost algorithm, and learn the AdaBoost model building in Python.
In recent years, boosting algorithms got huge popularity in data science or machine learning competitions. Most of the winners of these competitions use boosting algorithms to achieve high accuracy. These Data science competitions provide the global platform for learning, exploring, and providing solutions for various business and government problems. Boosting algorithms combine multiple low accuracy(or weak) models to create a high accuracy(or strong) models. It can be utilized in various domains such as credit, insurance, marketing, and sales. Boosting algorithms such as AdaBoost, Gradient Boosting, and XGBoost are widely used machine learning algorithm to win the data science competitions. In this tutorial, you are going to learn the AdaBoost ensemble boosting algorithm and the following topics will be covered:
- Ensemble Machine Learning Approach
- AdaBoost Classifier
- How does the AdaBoost algorithm work?
- Building Model in Python
- Pros and cons
- Conclusion
For more such tutorials, projects, and courses visit DataCamp
Ensemble Machine Learning Approach
An ensemble is a composite model, combines a series of low performing classifiers with the aim of creating an improved classifier. Here, individual classifier vote and final prediction label returned that performs majority voting. Ensembles offer more accuracy than individual or base classifiers. Ensemble methods can parallelize by allocating each base learner to different-different machines. Finally, you can say, Ensemble learning methods are meta-algorithms that combine several machine learning methods into a single predictive model to increase performance. Ensemble methods can decrease variance using the bagging approach, bias using a boosting approach, or improve predictions using the stacking approach.

- Bagging stands for bootstrap aggregation. combines multiple learners in a way to reduce the variance of estimates. For example, random forest trains M Decision Tree, you can train M different trees on different random subsets of the data and perform voting for final prediction. Bagging ensembles methods are Random Forest and Extra Trees.
- Boosting algorithms are a set of low accurate classifier to create a highly accurate classifier. Low accuracy classifier (or weak classifier) offers the accuracy better than the flipping of a coin. A highly accurate classifier( or strong classifier) offers an error rate close to 0. The boosting algorithm can track the model who failed the accurate prediction. Boosting algorithms are less affected by the overfitting problem. The following three algorithms have gained huge popularity in data science competitions.
- AdaBoost (Adaptive Boosting)
- Gradient Tree Boosting
- XGBoost
3. Stacking(or stacked generalization) is an ensemble learning technique that combines multiple base classification models predictions into a new data set. This new data are treated as the input data for another classifier. This classifier employed to solve this problem. Stacking is often referred to as blending.
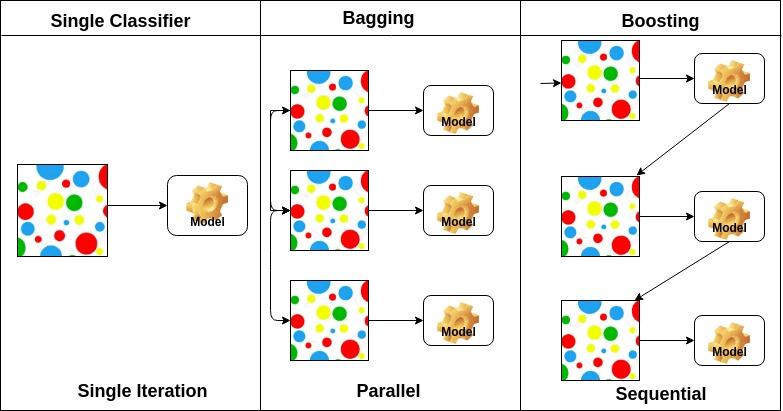
On the basis of the arrangement of base learners, ensemble methods can be divided into two groups: In parallel ensemble methods, base learners are generated in parallel for example. Random Forest. In sequential ensemble methods, base learners are generated sequentially for example AdaBoost.
On the basis of the type of base learners, ensemble methods can be divided into two groups: the homogenous ensemble method uses the same type of base learner in each iteration. heterogeneous ensemble method uses the different types of base learners in each iteration.
AdaBoost Classifier
Ada-boost or Adaptive Boosting is one of the ensemble boosting classifiers proposed by Yoav Freund and Robert Schapire in 1996. It combines multiple classifiers to increase the accuracy of classifiers. AdaBoost is an iterative ensemble method. AdaBoost classifier builds a strong classifier by combining multiple poorly performing classifiers so that you will get high accuracy strong classifier. The basic concept behind Adaboost is to set the weights of classifiers and training data samples in each iteration such that it ensures the accurate predictions of unusual observations. Any machine learning algorithm can be used as a base classifier if it accepts weights on the training set. Adaboost should meet two conditions:
- The classifier should be trained iteratively on various weighted training examples.
- In each iteration, It tries to provide a good fit to these examples by minimizing training error.
How does the AdaBoost algorithm work?
It works in the following steps:
- Initially, Adaboost selects a training subset randomly.
- It iteratively trains the AdaBoost machine learning model by selecting the training set based on the accurate prediction of the last training.
- It assigns the higher weight to wrong classified observations so that in the next iteration these observations will get a high probability for classification.
- Also, It assigns the weight to the trained classifier in each iteration according to the accuracy of the classifier. The more accurate classifier will get high weight.
- This process iterate until the complete training data fits without any error or until reached the specified maximum number of estimators.
- To classify, perform a “vote” across all of the learning algorithms you built.

Building Model in Python
Importing Required Libraries
Let’s first load the required libraries.
# Load libraries
from sklearn.ensemble import AdaBoostClassifier
from sklearn import datasets
# Import train_test_split function
from sklearn.model_selection import train_test_split
#Import scikit-learn metrics module for accuracy calculation
from sklearn import metricsLoading Dataset
In the model the building part, you can use the IRIS dataset, which is a very famous multi-class classification problem. This dataset comprises 4 features (sepal length, sepal width, petal length, petal width) and a target (the type of flower). This data has three types of flower classes: Setosa, Versicolour, and Virginia. The dataset is available in the scikit-learn library or you can also download it from the UCI Machine Learning Library.
# Load data
iris = datasets.load_iris()
X = iris.data
y = iris.targetSplit dataset
To understand model performance, dividing the dataset into a training set and a test set is a good strategy.
Let’s split dataset by using function train_test_split(). you need to pass basically 3 parameters features, target, and test_set size.
# Split the dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testBuilding AdaBoost Model
Let’s create the AdaBoost Model using Scikit-learn. AdaBoost uses the Decision Tree Classifier as a default Classifier.
# Create adaboost classifer object
abc = AdaBoostClassifier(n_estimators=50,learning_rate=1)
# Train Adaboost Classifer
model = abc.fit(X_train, y_train)
#Predict the response for test dataset
y_pred = model.predict(X_test)The most important parameters are base_estimator, n_estimators, and learning_rate.
- base_estimator: It is a weak learner used to train the model. It uses DecisionTreeClassifier as a default weak learner for training purposes. you can also specify different machine learning algorithms.
- n_estimators: Number of weak learners to train iteratively.
- learning_rate: It contributes to the weights of weak learners. It uses 1 as a default value.
Evaluate Model
Let’s estimate, how accurately the classifier or model can predict the type of cultivars.
Accuracy can be computed by comparing actual test set values and predicted values.
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Output:Accuracy: 0.8888888888888888
Well, you got an accuracy of 88.88%, considered as good accuracy.
For further evaluation, you can also create a model using different Base Estimators.
Using Different Base Learners
I have used SVC as a base estimator, you can use any ML learner as a base estimator if it accepts sample weight such as Decision Tree, Support Vector Classifier.
# Load libraries
from sklearn.ensemble import AdaBoostClassifier
# Import Support Vector Classifier
from sklearn.svm import SVC
# Import scikit-learn metrics module for accuracy calculation
from sklearn import metrics
# create base classifier
svc=SVC(probability=True, kernel='linear')
# Create adaboost classifier object
abc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)
# Train Adaboost Classifer
model = abc.fit(X_train, y_train)
# Predict the response for test dataset
y_pred = model.predict(X_test)
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Output:Accuracy: 0.9555555555555556
Well, you got a classification rate of 95.55%, considered as good accuracy.
In this case, SVC Base Estimator is getting better accuracy than the Decision tree Base Estimator.
Pros
AdaBoost is easy to implement. It iteratively corrects the mistakes of the weak classifier and improves accuracy by combining weak learners. You can use many base classifiers with AdaBoost. AdaBoost is not prone to overfitting. This can be found out via experiment results but there is no concrete reason available.
Cons
AdaBoost is sensitive to noise data. It is highly affected by outliers because it tries to fit each point perfectly. AdaBoost is slower compared to XGBoost.
Conclusion
Congratulations, you have made it to the end of this tutorial!
In this tutorial, you have learned the Ensemble Machine Learning Approaches, AdaBoost algorithm, it’s working, model building, and evaluation using the Python Scikit-learn package. Also, discussed its pros and cons.
I look forward to hearing any feedback or questions. you can ask the question by leaving a comment and I will try my best to answer it.
Originally published at https://www.datacamp.com/community/tutorials/naive-bayes-scikit-learn
Do you want to learn data science, check out on DataCamp.
For more such article, you can visit my blog Machine Learning Geek
Reach out to me on Linkedin: https://www.linkedin.com/in/avinash-navlani/


