
Introduction to Cluster Analysis
Classification of objects or cases into groups is one of the most significant concepts in Data Science and Machine Learning. Cluster analysis is a classification technique that is used to group similar objects into respective categories called clusters.
The objects are grouped such that for those in the same group, their degree of association is greater as compared to two objects in two different groups. It can be depicted using a simple diagram:
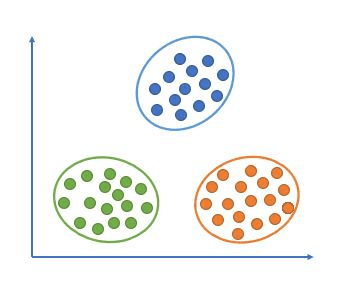
The figure gives a diagrammatic representation of clustering. Thus, we can say that there are three clusters present in the data. Similar data points are grouped together, and data points from different clusters are highly dissimilar. Distances between two clusters (i.e., inter-cluster distances) are maximized, while distances between two objects of a cluster (i.e., intra-cluster distances) are minimized. The distance mentioned is generally Euclidean distance or its square. There are various other distance or similarity metrics that can be used, such as Manhattan distance, Mahalanobis distance, etc. Their expressions for n-dimensional space is:
Euclidean Distance:
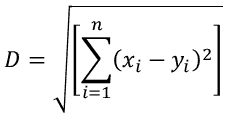
Manhattan Distance:
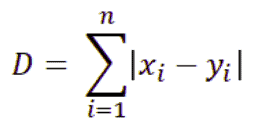
In cluster analysis, there is no prior information about the group membership for the objects of the data. Clustering, hence, can be called as an unsupervised classification as the labels are derived from data.
Cluster analysis is significant in a wide variety of Data Science applications as it helps identify and define patterns between data elements. Cluster analysis can also handle high dimensional data.
Applications of Cluster Analysis
- In market research, Cluster analysis is often used to identify groups within specified demographics
- Developing and identifying market segments
- Grouping cells or genes with similar functionalities in the field of Biology
- Classifying content on the web
- In image processing, for identifying patterns in the images
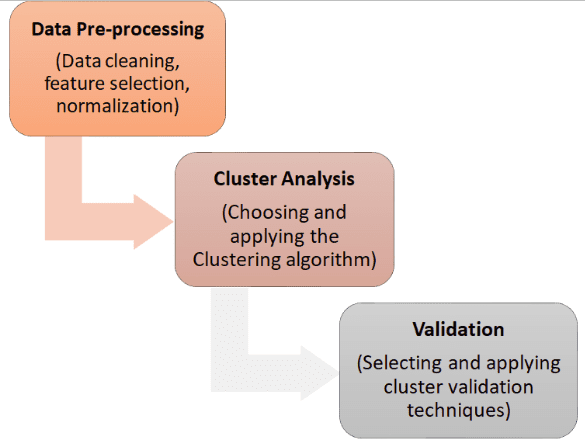
Flowchart for Cluster Analysis procedure
The general way of the workflow of Cluster Analysis is:
Methods of Cluster Analysis
There are various different methods of Cluster Analysis. Some popular methods are:
- Hierarchical Methods
- Agglomerative Clustering
- Divisive Clustering approach
- Partitioning Method (K-means)
- Grid-Based Method
- Density-based Method (DBSCAN)
- Model-Based Method of Clustering
- Constraint-based Method of Clustering
We will look into these in the upcoming articles.
Summary
This article was an introduction to one of the most popular Data Analytics concepts – Cluster Analysis. In the upcoming articles, we will look into details about the clustering methods, the algorithms, etc.


