
Latent Semantic Indexing using Scikit-Learn
In this tutorial, we will focus on Latent Semantic Indexing or Latent Semantic Analysis and perform topic modeling using Scikit-learn. If you want to implement topic modeling using Gensim then you can refer to this Discovering Hidden Themes of Documents article.
What is Topic Modelling?
Topic Modelling is an unsupervised technique for discovering the themes of given documents. It extracts the set of co-occurring keywords. These co-occurring keywords represent a topic. For example, stock, market, equity, mutual funds will represent the ‘stock investment’ topic.
What is Latent Semantic Indexing?
Latent Semantic Indexing(LSI) or Latent Semantic Analysis (LSA) is a technique for extracting topics from given text documents. It discovers the relationship between terms and documents. LSI concept is utilized in grouping documents, information retrieval, and recommendation engines. LSI discovers latent topics using Singular Value Decomposition.
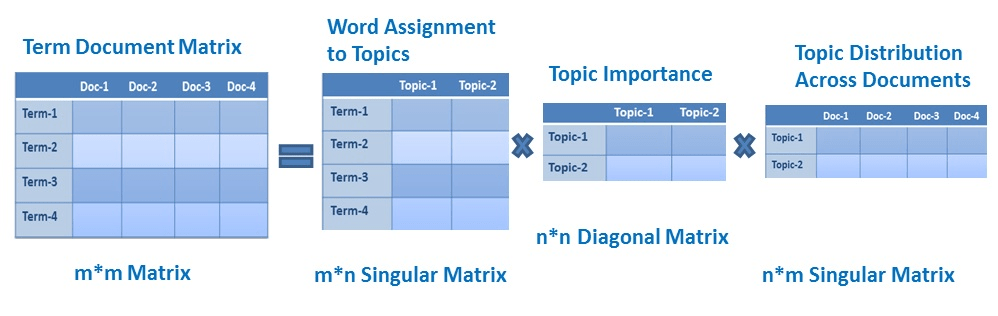
Implement LSI using Scikit learn
Load Data
In this step, you will load the dataset. You can download data from the following link:
import os
import pandas as pd
from nltk.tokenize import RegexpTokenizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
# Load Dataset
documents_list = []
with open( os.path.join("articles.txt") ,"r") as fin:
for line in fin.readlines():
text = line.strip()
documents_list.append(text)Generate TF-IDF Features
In this step, you will generate the TF-IDF matrix for given documents. Here, you will also perform preprocessing operations such as tokenization, and removing stopwords.
# Initialize regex tokenizer
tokenizer = RegexpTokenizer(r'\w+')
# Vectorize document using TF-IDF
tfidf = TfidfVectorizer(lowercase=True,
stop_words='english',
ngram_range = (1,1),
tokenizer = tokenizer.tokenize)
# Fit and Transform the documents
train_data = tfidf.fit_transform(documents_list) Perform SVD
SVD is a matrix decomposition technique that factorizes matrix in the product of matrices. Scikit-learn offers TruncatedSVD for performing SVD. Let’s see the example below:
# Define the number of topics or components
num_components=10
# Create SVD object
lsa = TruncatedSVD(n_components=num_components, n_iter=100, random_state=42)
# Fit SVD model on data
lsa.fit_transform(train_data)
# Get Singular values and Components
Sigma = lsa.singular_values_
V_transpose = lsa.components_.TExtract topics and terms
After performing SVD, we need to extract the topics from the component matrix. Let’s see the example below:
# Print the topics with their terms
terms = tfidf.get_feature_names()
for index, component in enumerate(lsa.components_):
zipped = zip(terms, component)
top_terms_key=sorted(zipped, key = lambda t: t[1], reverse=True)[:5]
top_terms_list=list(dict(top_terms_key).keys())
print("Topic "+str(index)+": ",top_terms_list)Output:
Topic 0: ['s', 'trump', 'said', 'eu', 't']
Topic 1: ['trump', 'clinton', 'republican', 'donald', 'cruz']
Topic 2: ['s', 'league', 'season', 'min', 'leicester']
Topic 3: ['eu', 'league', 'min', 'season', 'brexit']
Topic 4: ['bank', 'banks', 'banking', 'rbs', 'financial']
Topic 5: ['health', 'nhs', 'care', 'mental', 'patients']
Topic 6: ['min', 'ball', 'corner', 'yards', 'goal']
Topic 7: ['facebook', 'internet', 'online', 'users', 'twitter']
Topic 8: ['film', 'films', 'movie', 'women', 'director']
Topic 9: ['labour', 'party', 'bank', 'corbyn', 'film']
In the above example, you can see the 10 topics. If you see keywords of Topic 0([‘s’, ‘trump’, ‘said’, ‘EU’, ‘t’]) represents US Politics and Europe. Similarly, Topic 1 is about US Elections and Topic 2 is about Football League. This is how you can identify topics from the list of tags. Here we have taken 10 topics you can try with different topics and check the performance How it is making sense. For choosing a number of topics you can also use topic coherence explained in Discovering Hidden Themes of Documents article.
Summary
In this tutorial, you covered Latent Semantic Analysis using Scikit learn. LSA is faster and easy to implement. LSA unable to capture the multiple semantic of words. Its accuracy is lower than LDA( latent Dirichlet allocation). Topic modeling offers various usecases in Resume Summarization, Search Engine Optimization, Recommender System Optimization, Improving Customer Support, and the healthcare industry.


