Spotify Song Recommender System in Python
Build a Song Recommender System using Content-Based Filtering in Python.
With the rapid growth in online and mobile platforms, lots of music platforms are coming into the picture. These platforms are offering songs lists from across the globe. Every individual has a unique taste for music. Most people are using Online music streaming platforms such as Spotify, Apple Music, Google Play, or Pandora.
Online Music listeners have lots of choices for the song. These customers sometimes get very difficult in selecting the songs or browsing the long list. The service providers need an efficient and accurate recommender system for suggesting relevant songs. As data scientists, we need to understand the patterns in music listening habits and predict the accurate and most relevant recommendations.
In this tutorial, we are going to cover the following topics:
Content-Based Song Recommender System
The content-based filtering method is based on the analysis of item features. It determines which features are most important for suggesting the songs. For example, if the user has liked a song in the past and the feature of that song is the theme and that theme is party songs then Recommender System will recommend the songs based on the same theme. So the system adapts and learns the user behavior and suggests the items based on that behavior. In this article, we are using the Spotify dataset to discover similar songs for recommendation using cosine similarity and sigmoid kernel.
Loading Dataset
In this tutorial, you will build a book recommender system. You can download this dataset from here.
Let’s load the data into pandas dataframe:
import pandas as pd
from sklearn.metrics.pairwise import sigmoid_kernel
from sklearn.metrics.pairwise import cosine_similarity
from sklearn import preprocessing
df=pd.read_csv("data.csv")
df.head(Output:
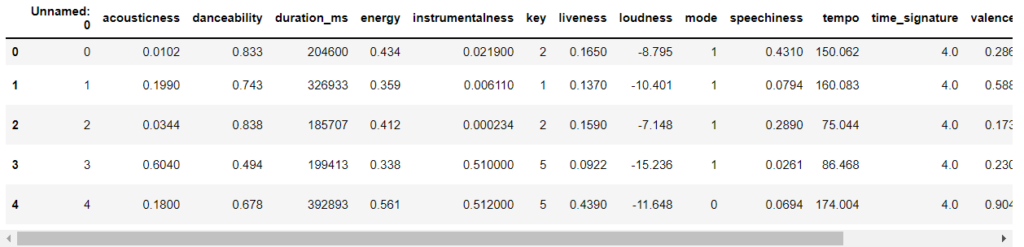
Understanding the Dataset
Let’s understand the dataset. In this dataset, we have 15 columns: acousticness, danceability, duration_ms, energy, instrumentalness, key, liveness, loudness, mode, speechiness, tempo, time_signature, valence, target, song_title, artist.
- Acosticness confidence measure from 0.0 to 1.0 of whether the track is acoustic.
- Danceability measure describes how suitable a track is for dancing.
- duration_ms is the duration of the song track in milliseconds.
- Energy represents a perceptual measure of intensity and activity.
- Instrumentalness predicts whether a track contains vocals or not.
- Loudness of a track in decibels(dB).
- Liveness detects the presence of an audience in the recording.
- Speechiness detects the presence of spoken words in a track
- Time_signature is an estimated overall time signature of a track.
- Key the track is in. Integers map to pitches using standard Pitch Class notation.
- Valence measures from 0.0 to 1.0 describing the musical positiveness conveyed by a track.
- Target value describes the encoded value of 0 and 1. 0 means listener has not saved the song and 1 means listener have saved the song.
- Tempo is in beats per minute (BPM).
- Mode indicates the modality(major or minor) of the song.
- Song_title is the name of the song.
- Artist is the singer of the song.
df.info()Output: <class 'pandas.core.frame.DataFrame'> RangeIndex: 2017 entries, 0 to 2016 Data columns (total 17 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Unnamed: 0 2017 non-null int64 1 acousticness 2017 non-null float64 2 danceability 2017 non-null float64 3 duration_ms 2017 non-null int64 4 energy 2017 non-null float64 5 instrumentalness 2017 non-null float64 6 key 2017 non-null int64 7 liveness 2017 non-null float64 8 loudness 2017 non-null float64 9 mode 2017 non-null int64 10 speechiness 2017 non-null float64 11 tempo 2017 non-null float64 12 time_signature 2017 non-null float64 13 valence 2017 non-null float64 14 target 2017 non-null int64 15 song_title 2017 non-null object 16 artist 2017 non-null object dtypes: float64(10), int64(5), object(2) memory usage: 268.0+ KB
Perform Feature Scaling
Before building the model, first we normalize or scale the dataset. For scaling it we are using MinMaxScaler of Scikit-learn library.
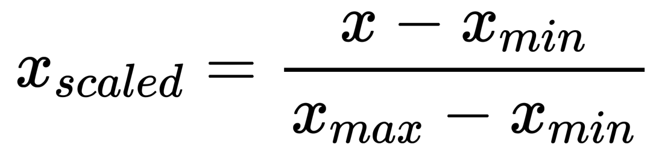
feature_cols=['acousticness', 'danceability', 'duration_ms', 'energy',
'instrumentalness', 'key', 'liveness', 'loudness', 'mode',
'speechiness', 'tempo', 'time_signature', 'valence',]
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
normalized_df =scaler.fit_transform(df[feature_cols])
print(normalized_df[:2])Building Recommender System using Cosine Similarity
In this section, we are building a content-based recommender system using similarity measures such as Cosine and Sigmoid Kernel. Here, we will find the similarities among items or songs feature set and pick the top 10 most similar songs and recommend them.
Cosine similarity measures the cosine angle between two feature vectors. Its value implies that how two records are related to each other. Cosine similarity can be computed for the non-equal size of text documents.
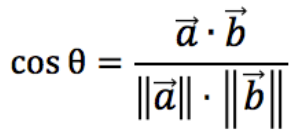
# Create a pandas series with song titles as indices and indices as series values
indices = pd.Series(df.index, index=df['song_title']).drop_duplicates()
# Create cosine similarity matrix based on given matrix
cosine = cosine_similarity(normalized_df)
def generate_recommendation(song_title, model_type=cosine ):
"""
Purpose: Function for song recommendations
Inputs: song title and type of similarity model
Output: Pandas series of recommended songs
"""
# Get song indices
index=indices[song_title]
# Get list of songs for given songs
score=list(enumerate(model_type[indices['Parallel Lines']]))
# Sort the most similar songs
similarity_score = sorted(score,key = lambda x:x[1],reverse = True)
# Select the top-10 recommend songs
similarity_score = similarity_score[1:11]
top_songs_index = [i[0] for i in similarity_score]
# Top 10 recommende songs
top_songs=df['song_title'].iloc[top_songs_index]
return top_songsIn the above code, we have computed the similarity using Cosine similarity and returned the Top-10 recommended songs.
Recommeding songs
Let’s make a forecast using computed cosine similarity on the Spotify song dataset.
print("Recommended Songs:")
print(generate_recommendation('Parallel Lines',cosine).values)In the above code, we have generated the Top-10 song list based on cosine similarity.
Song Recommendations using Sigmoid Kernel
Let’s make a forecast using computed Sigmoid kernel on Spotify song dataset.
# Create sigmoid kernel matrix based on given matrix
sig_kernel = sigmoid_kernel(normalized_df)
print("Recommended Songs:")
print(generate_recommendation('Parallel Lines',sig_kernel).values)In the above code, we have generated the Top-10 song list based on Sigmoid Kernel.
Summary
Congratulations, you have made it to the end of this tutorial!
In this tutorial, we have built the song recommender system using cosine similarity and Sigmoid kernel. This developed recommender system is a content-based recommender system. In another article, we have developed the recommender system using collaborative filtering. You can check that article here Book Recommender System using KNN. You can also check another article on the NLP-based recommender system.