Apache Hive Hands-0n
In this tutorial, we will focus on Hadoop Hive for processing big data.
What is Hive?
Hive is a component in Hadoop Stack. It is an open-source data warehouse tool that runs on top of Hadoop. It was developed by Facebook and later it is donated to the Apache foundation. It reads, writes, and manages big data tables stored in HDFS or other data sources.
Hive doesn’t offer insert, delete and update operations but it is used to perform analytics, mining, and report generation on the large data warehouse. Hive uses Hive query language similar to SQL. Most of the syntax is similar to the MySQL database. It is used for OLAP(Online Analytical Processing) purposes.
Why we need Hive?
In the year 2006, Facebook was generating 10 GB of data per day and in 2007 its data increased by 1TB per day. After few days, it is generating 15 TB of data per day. Initially, Facebook is using the Scribe server, Oracle database, and Python scripts for processing large data sets. As Facebook started gathering data then they shifted to Hadoop as its key tool for data analysis and processing.
Facebook is using Hadoop for managing its big data and facing problems for ETL operations because for each small operation they need to write the Java programs. They need a lot of Java resources that are difficult to find and Java is not easy to learn. So Facebook developed Hive which uses SQL-like syntaxes that are easy to learn and write. Hive makes it easy for people who know SQL just like other RDBMS tools.
Hive Features
The following are the features of the Hive.
- It is a Data Warehousing tool.
- It is used for enterprise data wrangling.
- It uses the SQL-like language HiveQL or HQL. HQL is a non-procedural and declaration language.
- It is used for OLAP operations.
- It increases productivity by reducing 100 lines of Java code into 4 lines of HQL queries.
- It supports Table, Partition, and Bucket data structures.
- It is built on top of Hadoop Distributed File System (HDFS)
- Hive supports Tez, Spark, and MapReduce.
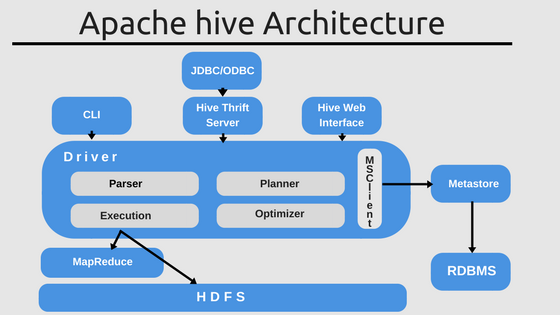
Hive Architecture
- Shell/CLI: It is an interactive interface for writing queries.
- Driver: Handle session, fetch and execute the operation
- Compiler: Parse, Plan and optimize the code.
- Execution: In this phase, MapReduce jobs are submitted to Hadoop. and jobs get executed.
- Metastore: Meta Store is a central repository that stores the metadata. It keeps all the details about tables, partitions, and buckets.
Hive Query Language(HQL) Practice
Starting HIVE
[cloudera@quickstart ~]$ hive
hive>
Database
hive> show databases;hive> create database emp;
hive> use emp;Tables
hive>create table employee(
> emp_id int,
> name string,
> location string,
> dep string,
> designation string,
> salary int)
> row format delimited fields terminated by ‘,’;Load the data from employee.txt file
employee.txt
101,Alice,New York,IT,Soft Engg,4000
102,Ali,Atlanta,Data Science,Sr Soft Engg,4500
103,Chang,New York,Data Science,Lead,6000
104,Robin,Chicago,IT,Manager,7000
hive> load data local inpath ‘/home/cloudera/employee.txt’ into table employee;
hive> select * from employee;Output:
hive>create table project(
> emp_id int,
> project_id int,
> pname string)
> row format delimited fields terminated by ‘,’;Load the data from project.txt file
project.txt
101,2001,Web Portal
102,2002,NER Model
103,2003,OCR Model
104,2004,Web Portal
hive> load data local inpath ‘/home/cloudera/project.txt’ into table employee;
hive> select * from project;Output:

Internal vs External Tables
The table you have created in the above subsection is an internal table or by default internal table. In order to create an external table, you have to use an external keyword as shown below syntax:
create external table project(
> emp_id int,
> project_id int,
> pname string)
> row format delimited fields terminated by ‘,’;External table also non as non-managed table. You can understand the difference between internal and external table form the following comparison:

Join
It is used to join two or more relations bases on the common column. Let’s perofrom the JOIN operation on employee and project table:
hive> select * from employee join project on employee.emp_id=project.emp_id;Output:

Group By
It can used to group the data based on given field or column in a table. Let’s see an example of Group By in the following query:
hive> select location, avg(salary) from employee group by location;Output:

Subquery
Subquery is an query with in query or nested query. Here, output of one query will become input for other query. Let’s see an example of sub query in th following query:
hive> select * from employee where employee.emp_id in (select emp_id from project where pname='Web Portal');Output:

Order By, Sort By, Distributed By, and Cluster By
- ORDER BY: It always assures global ordering. It is slower for large datasets because it pushes all the data into a single reducer. In the final output, you will get a single sorted output file.
- SORT BY: It orders the data at each reducer but the reducer may have overlapping ranges of data. In the final output, you will get multiple sorted output files.
- DISTRIBUTE BY: It ensures that each reducer will get non-overlapping ranges of data without sorting the data. In the final output, you will get multiple unsorted output files.
- CLUSTER BY: It ensures that each reducer will get non-overlapping ranges of data with sorted data on each reducer. It is a combination of DISTRIBUTE BY and SORT BY. In the final output, you will get multiple sorted output files. It always assures global ordering.

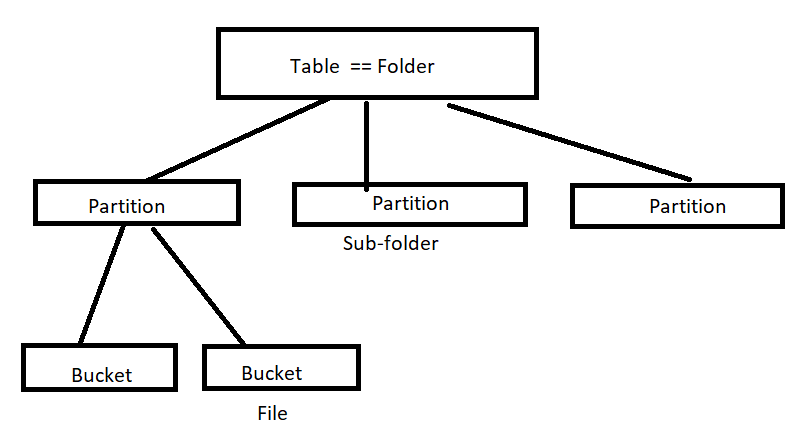
Table, Partition, and Bucket
- The table is an arrangement of data in grid form. This grid has rows and columns. It is widely used in maintaining and storing data records.
- Partitioning is used to distribute the data horizontally. It improves performance and organizes the data in a logical manner.
- The bucket is used for decomposing data into small manageable chunks.
- Hive query reads the entire data for each execution. This will reduce the performance due to a higher degree of input-output operations. Partitioning splits the data into manageable parts.
- Partitioning creates a partition for each unique value of a column. This may cause thousands of partitions. To avoid this problem bucketing can be used. In bucketing, we can limit the number of buckets. you can think of a bucket as a file and partition as a directory.
Hive Vs SQL
- In SQL, MapReduce is not Supported while in Hive MapReduce is Supported.
- Hive does not support update command due to the limitation and natural structure of HDFS, hive only has an insert overwrite for an update or insert functionality.
- HQL and SQL both fire queries in a database.
- In HQL, the queries are in the form of objects that are converted to SQL queries in the target database.
- SQL works with tables and columns while HIve works with classes and their properties.
- HQL supports concepts like polymorphism, inheritance, and association.
- HQL is like an object-oriented SQL.
- HIVE enforces that all the columns should be specified in the group by statement. For example: “select location, count(1) from employee;” doesn’t throw an error in Mysql but in Hive, you need to write “SELECT location, count(1) from employee group by location”. Otherwise, the hive won’t run.
Hive Limitations
The following are the limitations of the Hive.
- Hive is suitable for batch processing but doesn’t suitable for real-time data handling.
- Update and delete are not allowed, but we can delete in bulk i.e. we can delete the entire table but not individual observation.
- Hive is not suitable for OLTP(Online Transactional Processing) operations.
Summary
In this tutorial, we have discussed Apache Hive Features, Architecture, Components, and Limitations. We have also compared the Hive Vs SQL, Various operations( such as Order By, Sort By, Distributed By, and Cluster By ), and Partitions Vs Buckets. Also, We have executed the HQL in Hive and performed various operations such as loading data, Join, Group By, and Sub-queries.