
Apache Pig Hands-On
In this tutorial, we will focus on scripting language Apache PIG for processing big data.
Apache Pig is a scripting platform that runs top on Hadoop. It is a high-level and declarative language. It is designed for non-java programmers. Pig uses Latin scripts data flow language.
Why we need Pig?
Hadoop is written in Java and initially, most of the developers write map-reduce jobs in Java. It means till then Java is the only language to interact with the Hadoop system. Yahoo came with one scripting language known as Pig in 2009. Here are few other reasons why Yahoo developed the Pig.
- Lots of on-Programmers were unable to utilize MapReduce because they don’t know the Java programming language.
- It is difficult to maintain, optimize and write productive code.
- It is also difficult to consider all the MapReduce phases such as map, sort, and reduce during programming.
Yahoo’s managers have faced problems in performing small tasks. For each small and big change, they need to call the programming team. Also, programmers need to write lengthy codes for small tasks. To overcome these problems, yahoo developed a scripting platform Pig. Pig help researchers to analyze data with simple and few lines of declarative syntax.
Apache Pig Features
- Declarative Programming: An easy declarative programming language that is very similar to SQL.
- Non-programmer or non-Java programmers can easily write the big data task.
- Improves Productivity: It requires fewer coding lines. These fewer lines of code take less time in coding.
- It does not require metadata. For metadata, it relies on HDFS.
- It can handle structured, semi-structured, and unstructured data.
- It allows nested queries and processes them in parallel.
- It automatically optimizes the queries.
Apche Pig Architecture
- Parser: Parser used to check the syntax of the script. In syntax checking, it checks for data types and other miscellaneous checks. Parser outputs a Directed Acyclic Graph(DAG) that will show the logical operators.
- Optimizer: It ensures that the data in the pipeline should be minimum.
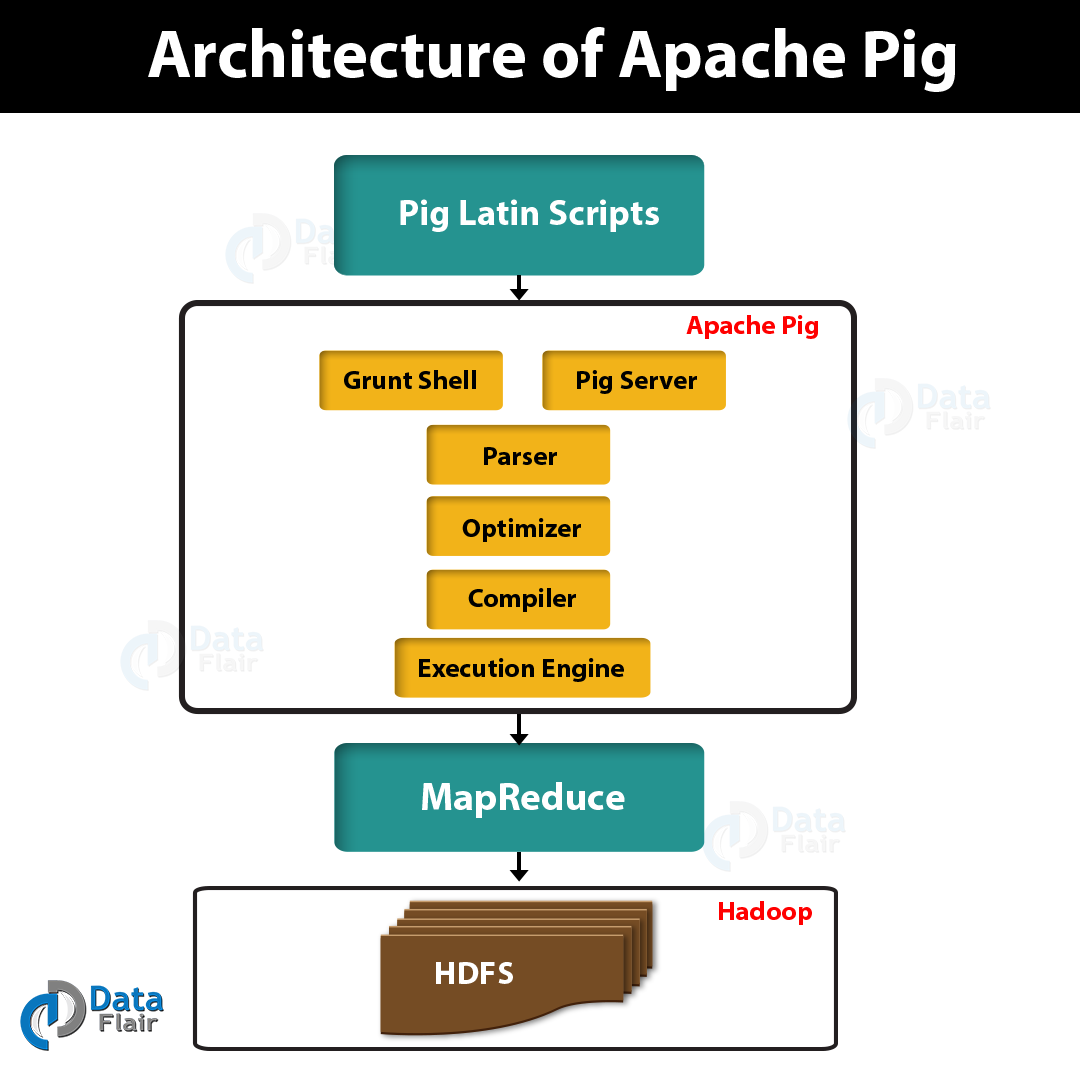
- Compiler: Then compiler compiles the optimized logical plan into a series of MapReduce jobs.
- Execution engine: In this phase, MapReduce jobs are submitted to Hadoop. and jobs get executed.
Apache Pig Components
Apache Pig offers two core components:
- Pig Latin: Pig Latin is a high-level and declarative scripting language similar to SQL that is easy to write and understand.
- Runtime Engine: It is an execution environment that converts its scripts into Java-based MapReduce jobs.
How does Apache Pig work?
Pig works in the following steps:
- Load Data: In this step, the dataset is loaded into the pig environment.
- Perform Operations: In this step, parsing, optimization, and compilation are performed on Pig Script.
- Execution: In this step, scripts are executed and final results were stored in HDFS.
Pig Practice
We can execute Pig in two modes: Local and MapReduce mode.
- Local mode: >> > pig -x local
- MapReduce Mode >>> pig
Operators
- JOIN: It is used to join two or more relations bases on the common column. Let’s create two files, in order to understand the JOIN operation:
file1.csv
EmpNr,location
5,The Hague
3,Amsterdam
9,Rotterdam
10,Amsterdam
12,The Hagueefile2.csv
EmpNr,Salary
5,10000
3,5000
9,2500
10,6000
12,4000Lets perform operations in to the Pig environment:
grunt> file1 = LOAD ‘file1’ Using PigStorage(‘,’) as (emp_no:int, location:chararray);
grunt> file2 = LOAD ‘file2’ Using PigStorage(‘,’) as (emp_no:int, salary:int);
grunt> joined = JOIN file1 BY(emp_no), file2 by (emp_no);
grunt> STORE joined INTO ‘out’;
grunt> DUMP joined;Output:
(3,Amsterdam,3,5000)
(5,The Hague,5,10000)
(9,Rotterdam,9,2500)
(10,Amsterdam,10,6000)
(12,The Hague,12,4000)
- FILTER: It is used to select the tuples from the relation with given condition. Lets perform FILTER operations in to the Pig environment:
grunt> file2 = LOAD ‘file2’ Using PigStorage(‘,’) as (emp_no:int, salary:int);
grunt> filtered= FILTER file2 BY salary>5000;
grunt> STORE filtered INTO ‘out1’;
grunt> dump filtered;Output:
(5,10000)
(10,6000)
- GROUP: It can used to group the data based on given field.
grunt> grp = GROUP joined BY location;
grunt> STORE grp INTO ‘out1’;
grunt> DUMP grp;Output:
(Amsterdam,{(10,Amsterdam,10,6000),(3,Amsterdam,3,5000)})
(Rotterdam,{(9,Rotterdam,9,2500)})
(The Hague,{(12,The Hague,12,4000),(5,The Hague,5,10000)})
- FOREACH: It is used to apply transformation on columns of a relation. Lets perform FOREACH operations in to the Pig environment:
grunt> out = FOREACH grp GENERATE group, COUNT(joined.location) as count;
grunt> STORE out INTO ‘out1’;
grunt> DUMP out;Output:
(Amsterdam,2)
(Rotterdam,1)
(The Hague,2)
- UNION: It is used to merge the content of the two relations.
- DISTINCT: It is used to remove the duplicates from the relation.
- LIMIT: It is used to limit the number of output tuples.
grunt> LIMIT file1 2Output: (5,The Hague)
(3,Amsterdam)
EVAL Function
- AVG: Computes the average of the numeric column in a given relation.
- MAX: Computes the maximum of the numeric column in a given relation.
- COUNT: Computes the count of the numeric column in a given relation.
Word Count Problem
We can count the occurrence of words in a given input file in PiG. Lets see the script below:
lines = LOAD ‘file_demo.txt’ AS (line:chararray);
words = FOREACH lines GENERATE FLATTEN(TOKENIZE(line)) as word;
grouped = GROUP words BY word;
wordcount = FOREACH grouped GENERATE group, COUNT(words);
DUMP wordcount;Output:
(PM,1)
(in,1)
(of,1)
(on,1)
(to,1)
(CMs,1)
(and,1)
(Modi,1)
(India,2)
(fresh,1)
(Health,1)
(issues,1)
(speaks,1)
(states,1)
(Vaccine,1)
(hotspot,1)
(Lockdown,1)
(Ministry,1)
(Shortage,1)
(Extension,1)
(guidelines,1)
(management,1)
(Coronavirus,3)
(containment,1)
Compare Hadoop MapReduce, Hive, and Pig

Summary
In this tutorial, we have discussed Hadoop PIG Features, Architecture, Components, and its working. Also, we have discussed the scripting in Pig and experimented with operators, and implemented a word count program in Pig.


