Text Analytics for Beginners using Python NLTK
Learn how to analyze text using NLTK.
In today’s area of the internet and online services, data is generating at incredible speed and amount. Generally, Data analysts, engineers, and scientists are handling relational or tabular data. These tabular data columns have either numerical or categorical data. Generated data has a variety of structures such as text, image, audio, and video. Online activities such as articles, website text, blog posts, social media posts are generating unstructured textual data.
Corporate and businesses need to analyze textual data to understand customer activities, opinions, and feedback to successfully derive their business. To compete with big textual data, text analytics is evolving at a faster rate than ever before.
Text Analytics has lots of applications in today’s online world. by analyzing tweets on Twitter, we can find tending news, people’s reactions to a certain event. Amazon can understand user feedback or review on a certain product. BookMyShow can find people’s opinions about the movie. Youtube can also analyze understand people’s viewpoints on a video.
For more such tutorials and courses visit DataCamp:
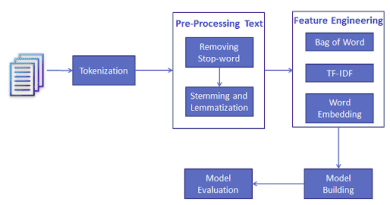
In this tutorial, you are going to cover the following topics:
- Text Analytics and NLP
- Compare Text Analytics, NLP, and Text Mining
- Text Analysis Operations using NLTK
- Tokenization
- Stopwords
- Lexicon Normalization such as Stemming and Lemmatization
- POS Tagging
Text Analytics and NLP
Text communication is one of the most popular forms of day-to-day conversion. We chat, message, tweet, share status, email, write blogs, share opinions, and feedback in our daily routine. These all activities are generating text in a large amount, which is unstructured in nature. In the area of the online marketplace and social media, It is extremely important to analyze large quantities of data, to understand people’s opinions.
NLP enables the computer to interact with humans in a natural manner. It helps the computer to understand the human language and derive meaning from it. NLP is applicable in several problems from speech recognition, language translation, classifying documents to information extraction. Analyzing movie reviews is one of the classic examples to demonstrate a simple NLP Bag-of-words model. on movie reviews.
Compare Text Analytics, NLP and Text Mining
Text mining is also referred to as text analytics. Text mining is a process of exploring large textual data and find patterns. Text Mining process the text itself, while the NLP process the underlying metadata. Finding frequency counts of words, length of the sentence, presence/absence of specific words is known as text mining. Natural language processing is one of the components of text mining. NLP helps identified sentiment, finding entities in the sentence, and categorize of blog/article. Text mining is preprocessed data for text analytics. In Text Analytics, statistical and machine learning algorithms are used to classify information.
Text Analysis Operations using NLTK
NLTK is a powerful Python package that provides a set of diverse natural language algorithms. It is free, open source, easy to use, large community, and well documented. NLTK consists of the most common algorithms such as tokenizing, part-of-speech tagging, stemming, sentiment analysis, topic segmentation, and named entity recognition. NLTK helps the computer to analyze, preprocess, and understand the written text.
!pip install nltkTokenization
Tokenization is the first step in text analytics. The process of breaking down text paragraphs into smaller chunks such as words or sentences is called Tokenization. The token is a single entity that is building blocks for sentences or paragraphs.
Sentence Tokenization
Sentence tokenizer breaks text paragraph into sentences.
from nltk.tokenize import sent_tokenize
text="""Hello Mr. Smith, how are you doing today? The weather is great, and city is awesome.The sky is pinkish-blue. You shouldn't eat cardboard"""
tokenized_text=sent_tokenize(text)
print(tokenized_text)Output:['Hello Mr. Smith, how are you doing today?', 'The weather is great, and city is awesome.', 'The sky is pinkish-blue.', "You shouldn't eat cardboard"]
Here, the given text is tokenized into sentences.
Word Tokenization
Word tokenizer breaks text paragraphs into words.
from nltk.tokenize import word_tokenize
tokenized_word=word_tokenize(text)
print(tokenized_word)Output: ['Hello', 'Mr.', 'Smith', ',', 'how', 'are', 'you', 'doing', 'today', '?', 'The', 'weather', 'is', 'great', ',', 'and', 'city', 'is', 'awesome', '.', 'The', 'sky', 'is', 'pinkish-blue', '.', 'You', 'should', "n't", 'eat', 'cardboard']
Frequency Distribution
from nltk.probability import FreqDist
fdist = FreqDist(tokenized_word)
print(fdist.most_common(2))Output:[('is', 3), (',', 2)]
# Frequency Distribution Plot
import matplotlib.pyplot as plt
fdist.plot(30,cumulative=False)
plt.show()Output:

Stopwords
Stopwords are considered noise in text. Text may contain stop words such as is, am, are, this, a, an, the, etc.
In NLTK for removing stopwords, you need to create a list of stopwords and filter out your list of tokens from these words.
from nltk.corpus import stopwords
stop_words=set(stopwords.words("english"))
print(stop_words)
Output:
{'their', 'then', 'not', 'ma', 'here', 'other', 'won', 'up', 'weren', 'being', 'we', 'those', 'an', 'them', 'which', 'him', 'so', 'yourselves', 'what', 'own', 'has', 'should', 'above', 'in', 'myself', 'against', 'that', 'before', 't', 'just', 'into', 'about', 'most', 'd', 'where', 'our', 'or', 'such', 'ours', 'of', 'doesn', 'further', 'needn', 'now', 'some', 'too', 'hasn', 'more', 'the', 'yours', 'her', 'below', 'same', 'how', 'very', 'is', 'did', 'you', 'his', 'when', 'few', 'does', 'down', 'yourself', 'i', 'do', 'both', 'shan', 'have', 'itself', 'shouldn', 'through', 'themselves', 'o', 'didn', 've', 'm', 'off', 'out', 'but', 'and', 'doing', 'any', 'nor', 'over', 'had', 'because', 'himself', 'theirs', 'me', 'by', 'she', 'whom', 'hers', 're', 'hadn', 'who', 'he', 'my', 'if', 'will', 'are', 'why', 'from', 'am', 'with', 'been', 'its', 'ourselves', 'ain', 'couldn', 'a', 'aren', 'under', 'll', 'on', 'y', 'can', 'they', 'than', 'after', 'wouldn', 'each', 'once', 'mightn', 'for', 'this', 'these', 's', 'only', 'haven', 'having', 'all', 'don', 'it', 'there', 'until', 'again', 'to', 'while', 'be', 'no', 'during', 'herself', 'as', 'mustn', 'between', 'was', 'at', 'your', 'were', 'isn', 'wasn'}
Removing Stopwords
filtered_tokens=[]
for w in tokenized_word:
if w not in stop_words:
filtered_tokens.append(w)
print("Tokenized Words:",tokenized_word)
print("Filterd Tokens:",filtered_tokens)Output: Tokenized Words: ['Hello', 'Mr.', 'Smith', ',', 'how', 'are', 'you', 'doing', 'today', '?', 'The', 'weather', 'is', 'great', ',', 'and', 'city', 'is', 'awesome.The', 'sky', 'is', 'pinkish-blue', '.', 'You', 'should', "n't", 'eat', 'cardboard'] Filterd Tokens: ['Hello', 'Mr.', 'Smith', ',', 'today', '?', 'The', 'weather', 'great', ',', 'city', 'awesome.The', 'sky', 'pinkish-blue', '.', 'You', "n't", 'eat', 'cardboard']
Removing Punctuations
import string
# punctuations
punctuations=list(string.punctuation)
filtered_tokens2=[]
for i in filtered_tokens:
if i not in punctuations:
filtered_tokens2.append(i)
print("Filterd Tokens After Removing Punctuations:",filtered_tokens2)Output: Filterd Tokens After Removing Punctuations: ['Hello', 'Mr.', 'Smith', 'today', 'The', 'weather', 'great', 'city', 'awesome.The', 'sky', 'pinkish-blue', 'You', "n't", 'eat', 'cardboard']
Lexicon Normalization
Lexicon normalization considered as another type of noise in text. for example, connection, connected, connecting word reduce to a common word “connect”. It reduces derivationally related forms of a word to a common root word.
Stemming
Stemming is a process of linguistic normalization, which reduces words to their word root word or chops off the derivational affixes. for example, connection, connected, connecting word reduce to a common word “connect”.
# Stemming
from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize, word_tokenize
ps = PorterStemmer()
stemmed_words=[]
for w in filtered_tokens2:
stemmed_words.append(ps.stem(w))
print("Filtered Tokens After Removing Punctuations:",filtered_tokens2)
print("Stemmed Tokens:",stemmed_words)Output: Filtered Sentence: ['Hello', 'Mr.', 'Smith', ',', 'today', '?'] Stemmed Sentence: ['hello', 'mr.', 'smith', ',', 'today', '?']
Lemmatization
Lemmatization reduces words to their base word, which is linguistically correct lemmas. It transforms the root word with the use of vocabulary and morphological analysis. lemmatization is usually more sophisticated than stemming. Stemmer works on an individual word without knowledge of the context. For example, The word “better” has “good” as its lemma. This thing will miss by stemming because it requires a dictionary look-up.
#Lexicon Normalization#performing stemming and Lemmatization
from nltk.stem.wordnet import WordNetLemmatizer
from nltk.stem.porter import PorterStemmer
lem = WordNetLemmatizer()
stem = PorterStemmer()
word = "flying"
print("Lemmatized Word:",lem.lemmatize(word,"v"))
print("Stemmed Word:",stem.stem(word))Output: Lemmatized Word: fly Stemmed Word: fli
POS Tagging
The main target of Part-of-Speech(POS) tagging is to identify the grammatical group of a given word. Whether it is a NOUN, PRONOUN, ADJECTIVE, VERB, ADVERBS, etc. based on the context. POS Tagging looks for relationships within the sentence and assigns a corresponding tag to the word.
from nltk.tokenize import word_tokenize
from nltk import pos_tag
sent = "Albert Einstein was born in Ulm, Germany in 1879."
tokens=word_tokenize(sent)
pos_=pos_tag(tokens)
print("Tokens:",tokens)
print("PoS tags:",pos_)Output:
Tokens: ['Albert', 'Einstein', 'was', 'born', 'in', 'Ulm', ',', 'Germany', 'in', '1879', '.']
PoS tags: [('Albert', 'NNP'), ('Einstein', 'NNP'), ('was', 'VBD'), ('born', 'VBN'), ('in', 'IN'), ('Ulm', 'NNP'), (',', ','), ('Germany', 'NNP'), ('in', 'IN'), ('1879', 'CD'), ('.', '.')]
Named Entity Recognition
Named entity recognition is a more advanced form of language processing that identifies important elements like places, people, organizations, and languages within an input string of text. We can detect entities using ne_chunk() function available in NLTK. Let’s see the following code block:
from nltk import ne_chunk
sent="New York City on Tuesday declared a public health emergency and ordered mandatory measles vaccinations amid an outbreak, becoming the latest national flash point over refusals to inoculate against dangerous diseases."
for chunk in ne_chunk(nltk.pos_tag(word_tokenize(sent))):
if hasattr(chunk, 'label'):
print(chunk.label(), ' '.join(c[0] for c in chunk))Output:GPE New York City
Conclusion
Congratulations, you have made it to the end of this tutorial!
In this tutorial, you have learned What is Text Analytics, NLP, and text mining?, Basics of text analytics operations using NLTK such as Tokenization, Normalization, Stemming, Lemmatization, and POS tagging.
I look forward to hearing any feedback or questions. you can ask the question by leaving a comment and I will try my best to answer it.
Originally published at https://www.datacamp.com/community/tutorials/text-analytics-beginners-nltk