
Data Science Interview Questions Part-6 (NLP & Text Mining)
Top-25 frequently asked data science interview questions and answers on NLP and Text Mining for fresher and experienced Data Scientist, Data analyst, statistician, and machine learning engineer job role.
Data Science is an interdisciplinary field. It uses statistics, machine learning, databases, visualization, and programming. So in this sixth article, we are focusing on NLP and Text Mining questions.
Let’s see the interview questions.
1. What do you mean by natural language and computer language?
Natural language is a human language such as Hindi, English, and German. Designing computers that can understand natural languages is a challenging problem.
Computer language is a set of instructions that used to produce the desired output such as C, C++, Python, Julia, and Scala.
2. What is the difference between NLP and NLU?
Natural language processing is one of the components of text mining. NLP helps identified sentiments, finding entities in the sentence, and category of blog/article. Text Mining is about exploring large textual data and find patterns. It includes finding frequent words, the length of the sentence, and the presence/absence of specific words.
NLP is a combination of NLU(Natural Language Understanding) and NLG (Natural Langauge Generation). NLU is used to understand the meaning of a given input text. It understands based on the grammar and context of the text. NLU focuses on sentiment, semantics, context, and intent. For example, the questions “what’s the weather like outside?” and “how’s the weather?” are both asking the same thing. NLG generates text based on structured data. It takes data from a search result and returns it into understandable language.
3. What is sentiment analysis?
The business organization wants to understand the opinion of customers and the public. For example, what went wrong with their latest products? what users and the general public think about the latest feature? Quantifying the user’s content, idea, belief, and opinion are known as sentiment analysis. It is not only limited to marketing, but it can also be utilized in politics, research, and security. The sentiment is more than words, it is a combination of words, tone, and writing style.
4. What is tokenization?
Tokenization is the process of splitting text into small pieces, called tokens such as words, or sentences. It ignoring characters like punctuation marks (,. “ ‘) and spaces. Word tokenization is breaking up the text into individual words and Sentence tokenization is breaking up the text into individual sentences.
5. What is n-gram model?
The Bag-of-words model(BoW ) is the simplest way of extracting features from the text. BoW converts text into the matrix of the occurrence/frequency of words within a document. This model concerns whether given words occurred or not in the document. It can be a combination of two or more words, which is called the bigram or trigram model and the general approach is called the n-gram model. n-gram creates a matrix is known as the Document-Term Matrix(DTM) or Term-Document Matrix(TDM).
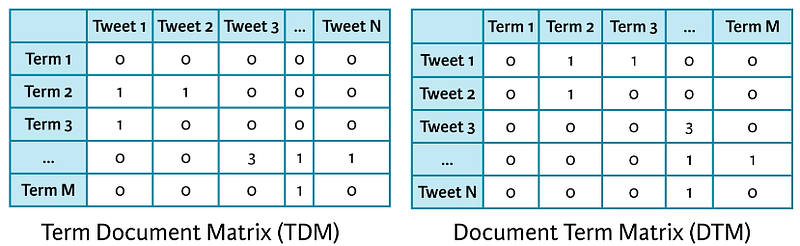
6. What is TF-IDF?
TF-IDF(Term Frequency-Inverse Document Frequency) normalizes the document term matrix. In Term Frequency(TF), you just count the number of words that occurred in each document. IDF(Inverse Document Frequency) measures the amount of information a given word provides across the document. IDF is the logarithmically scaled inverse ratio of the number of documents that contain the word and the total number of documents. TF-IDF is the multiplication of TF and IDF.
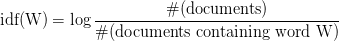
7. What is stemming and Lemmatization?
Stemming involves simply lopping off easily-identified prefixes and suffixes to produce what’s often the simplest version of a word. Connection, for example, would have the -ion suffix removed and be correctly reduced to connect.
Lemmatization is a way of dealing with the fact that while words like connect, connection, connecting, connected, etc. aren’t exactly the same, they all have the same essential meaning: connect.
lemmatization looks at words and their roots (called lemma) as described in the dictionary. It is more precise than stemming. Stemming reduces word-forms to (pseudo)stems, whereas lemmatization reduces the word-forms to linguistically valid lemmas. The word “better” has “good” as its lemma. This link is missed by stemming, as it requires a dictionary look-up.
8. What is PoS Tagging?
A word’s part of speech defines its function within a sentence. A noun, for example, identifies an object. An adjective describes an object. A verb describes the action. Identifying and tagging each word’s part of speech in the context of a sentence is called Part-of-Speech Tagging, or POS Tagging.
9. What is named entity recognition?
Named Entity recognition, also called entity detection, is a more advanced form of language processing that identifies important elements like places, people, organizations, and languages within an input string of text. This is really helpful for quickly extracting information from text since you can quickly pick out important topics or identify key sections of text.

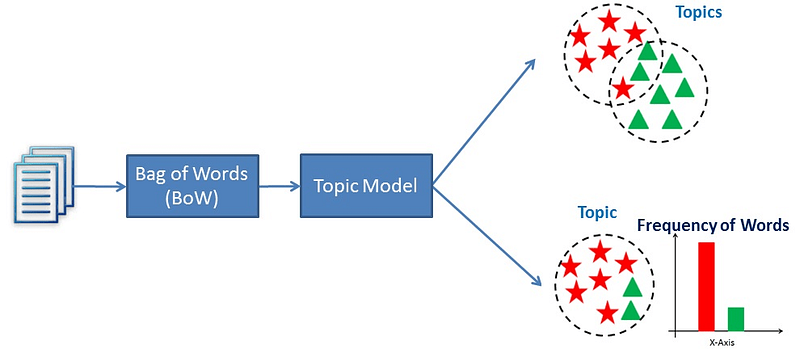
10. What is topic modeling?
Topic modeling is a text mining technique that provides methods to identify co-occurring keywords to summarize large collections of textual information. It helps in discovering hidden topics in the document, annotate the documents with these topics, and organize a large amount of unstructured data.
There is a possibility that a single document can associate with multiple themes. for example, group words such as ‘patient’, ‘doctor’, ‘disease’, ‘cancer’, ad ‘health’ will represent the topic ‘healthcare’. Topic Modelling is a different game compared to rule-based text searching that uses regular expressions.
11. How Latent Semantic Indexing works?
LSA (Latent Semantic Analysis) also known as LSI (Latent Semantic Index) LSA uses a bag of word(BoW) model, which results in the term-document matrix (occurrence of terms in a document). rows represent terms and columns represent documents.LSA learns latent topics by performing a matrix decomposition on the document-term matrix using Singular value decomposition. LSA is typically used as a dimension reduction or noise-reducing technique. LSA uses SVD(Singular Value Decomposition) for factorizing the Term document matrix(TDM) into 3 matrices singular, diagonal, and singular matrix.

12. How LDA works?
Latent Dirichlet Allocation(LDA) is an unsupervised algorithm for topic modeling. It helps users to detect the relationship between words and discover groups in those words. The core idea behind the topic modeling is that each document is represented by the distribution of topics and the topic is represented by the distribution of words. In other words, we can say first we connect words to the topic, and then topics will be connected by each document.
It is a kind of “generative probabilistic model”. LDA consists of two tables or matrices. The first table describes the probability of selecting a particular part when sampling a particular topic. The second table describes the chance of selecting a particular topic when sampling a particular document or composite.
13. Explain the masked language model?
Masked language modeling is an example of autoencoding language modeling. It is a kind of fill-in-the-blank task. It uses context words surrounded by mask tokens and predicts what word should be in the place of the mask. Masked language modeling is useful when trying to learn deep representations. BERT (Bidirectional Encoder Representations from Transformers) pre-trained model used the Masked Language model for model training.
14. what is perplexity?
In natural language processing, perplexity is a way of evaluating language models. A language model is a probability distribution over entire sentences or texts [Wikipedia]. Perplexity is a way to express a degree of confusion a model has in predicting. Perplexity is the exponentiation of the entropy. Low perplexity is good and high perplexity is bad since the perplexity is the exponentiation of the entropy.
15. How do you preprocess text in NLP?
Text Preprocessing involves the cleaning, normalizing, and noise removal from the given input text. text preprocessing involves the following steps:
- Lowercase all texts.
- Word and Sentence Tokenization
- Removing stopwords
- Handling contractions
- Removing punctuations, numbers, special characters, and extra whitespaces.
- Stemming and Lemmatization
16. What is Word Embeddings? How it is generated?
Word embedding converts text data (e.g words, sentences, and paragraphs) into some kind of vector representation. A word having the same meaning has a similar representation. Word embedding uses an embedding layer to learn vector representation of the given text using Backpropagation. Some examples of word embedding are Word2Vec, Sent2Vec, and Doc2Vec.
There are two models for learning word2vec models:
- The continuous Bag-of-Words (CBOW) model learns the embedding by predicting the current word based on its context.
- The continuous skip-gram model learns by predicting the surrounding words given a current word.
Word embeddings use very shallow Language Models and do not consider the context of the word into account.
17. How LSTM works?
LSTM stands for Long Short term memory. It is an extension in RNN(Recurrent Neural Networks). It mitigates the problem of vanishing gradient descent problem of RNN. In RNN, the neural network weights become very smaller or close to zero as we move backward in the network. Due to this problem neurons in the earlier layers learn very slow. This is also the reason that we don’t use the sigmoid and Tanh activation function. Nowadays, mostly we are using ReLu(Rectified Linear Unit) in hidden layers and sigmoid at the output layer.
LSTM uses gates to overcome this problem. It uses three gates: Input, Output, and Forget gate. Here, the gates control whether to store or delete (remember or forget) the information.
- The input gate is responsible for adding useful information to the cell state.
- Forget gate is responsible for removing information from the cell state.
- The output gate is responsible for selecting useful information from the current cell state.
18. How do you extract features in NLP?
In-Text Classification Problem, we have a set of texts and their respective labels. but we directly can’t use text for our model. you need to convert this text into some numbers or vectors of numbers. There are various ways to convert your text into some vector:
- BoW(Bag of words) or N-gram model
- TF-IDF
- Word Embeddings: Word2Vec, Sent2Vec, Doc2Vecs
- Advanced word embeddings such as Elmo, ULMFit, USE, GPT, BERT
- Transformers
19. What are some real-life NLP applications?
NLP offers the following real-life applications:
- Google Translation
- Spell and grammar correction
- Chatbots
- Summarizing news article
20. What is parsing?
Parsing helps us to understand the structure of text data. It has capability to analyze any sentence using the parse tree and verify the grammar of a sentence. SpaCy library implemented the dependency parsing.

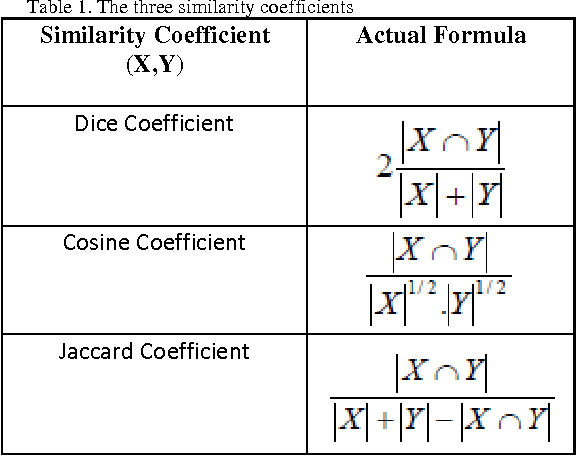
21. How do you find similarities between the two sentences?
We can find a similarity between two texts using Cosine and Jaccard similarity.
22. What are regular expressions?
Regular Expressions or Regex are searching patterns that used to search in textual data. It is helpful in extracting email addresses, hashtags, and phone numbers.
23. What is the major difference between CRF (Conditional Random Field) and HMM (Hidden Markov Model)?
- CRF is Discriminative whereas HMM is a Generative model.
- Conditional Random Fields is a sequential extension of the Maximum Entropy Model.
- CRF models are more powerful than HMMs due to their application of feature functions.
- Both HMMs and linear CRFs are typically trained with Maximum Likelihood techniques with gradient descent, Quasi-Newton methods, or for HMMs with Expectation-Maximization techniques. If the optimization problems are convex, these methods all yield the optimal parameter set.
24. What is BiLSTM?
BiLSTM is a Bidirectional LSTM that processed signals in both forward and backward directions. It is a sequential processing model that consists of two LSTM. This bidirectional nature helps us to increase the more contextual information for the algorithm. It shows quite good results when it understands the context better.
25. What is Syntactic and Semantic Analysis?
Syntactic analysis is analyzing the sentence and understand the grammar rules and order of sentence. It includes the following tasks parsing, word segmentation, morphological segmentation, stemming, and lemmatization.
Semantic analysis analyses the meaning and interpretation of a text. It includes the following tasks such as Named entity recognition, word sense ambiguation, and Natural language generation.
Summary
In this article, we have focused on NLP and Text Analytics interview questions. In the next article, we will focus on the interview questions related to Basic Statistics.
Data Science Interview Questions Part-7(Statistics)


